1. Einleitung
1.1 Feministische AI Literacies
Feministische AI Literacies in der Sozialen Arbeit verbindet drei Perspektiven:
- AI Literacies: Fähigkeit, KI-Werkzeuge kompetent und kritisch einzusetzen
- Feministisch: Macht- und Ungleichheitsverhältnisse bewusst mitdenken
- Androzentrismus erkennen: Männliche Perspektiven wurden historisch als Norm gesetzt: in der Wissenschaft, in Institutionen und in Technologien wie KI.
- Veränderung anstreben: Geschlechterverhältnisse ohne Hierarchien und mit gleichem Zugang zu Ressourcen.
- Sozialer Arbeit: Professionelle Haltung und fachliche Verantwortung als Rahmen
Mehr zu Feminismen in der Sozialen Arbeit: Kasten, A., von Bose, K. & Kalender, U. (Hrsg.). (2022). Feminismen in der Sozialen Arbeit. Debatten, Dis/Kontinuitäten, Interventionen. Weinheim & Basel: Beltz Juventa.
Definition
Feministische AI Literacies in der Sozialen Arbeit sind diversitäts- und machtsensible, intersektionale und Bias-erkennende Fähigkeiten und Fertigkeiten im Umgang mit generativen KI-Tools mit einem speziellen Fokus auf Prompting und kritische Output-Bewertung sowie Kontext- bzw. Anwendungssensitivität (Klinger & Sackl-Sharif, 2026).
Klinger, Sabine & Sackl-Sharif, Susanne (26.02.2026). Feministische AI Literacies in der Sozialen Arbeit [Definition]. In: Orientierungsleitfaden: Diversitätssensibler Umgang mit Künstlicher Intelligenz. digitalesozialearbeit.github.io/orientierungsleitfaden
1.2 Zentrale Haltung: Human-in-the-Loop
Die fachliche Entscheidung triffst immer du, nie die KI.
Wir betrachten KI nicht als „Wahrheitsmaschine", sondern als Werkzeug. Informierte Skepsis gepaart mit Mut zur Fehlerfreundlichkeit ist essenziell. KI-Systeme sind nicht neutral – sie können gesellschaftliche Machtverhältnisse und Diskriminierungsstrukturen reproduzieren.
1.3 Das EPIC-Modell
Ein ethischer Rahmen für dein Handeln: vier Prinzipien für die Integration von KI in die Soziale Arbeit.
KI kann bestehende Ungleichheiten und Diskriminierung reproduzieren. Du erkennst Bias und handelst verantwortungsvoll.
Professionelle Standards und politische Rahmenbedingungen müssen KI aktiv mitdenken. Du gestaltest Richtlinien mit und setzt dich für den Schutz vulnerabler Gruppen ein.
Die Integration von KI erfordert Zusammenarbeit über Fachgrenzen hinweg. Du vernetzt dich mit Fachleuten aus Technik, Politik und anderen Bereichen.
Adressat:innen sollen KI nicht nur nutzen, sondern mitgestalten können. Du beteiligst sie und stärkst ihre Fähigkeit, KI-generierte Inhalte kritisch einzuordnen.
Quelle: Boetto, H. (2025). Artificial Intelligence in Social Work: An EPIC Model for Practice. Australian Social Work. DOI: 10.1080/0312407X.2025.2488345
2. Basic Wissen KI
Wichtig: Dieser Leitfaden behandelt generative KI-Systeme (Textgeneratoren wie ChatGPT, Claude, Gemini). Er gilt nicht für prädiktive KI-Systeme, die in manchen Einrichtungen zur Risikoeinschätzung oder Fallanalyse eingesetzt werden. Diese werfen zum Teil andere ethische Fragen auf.
2.1 Was ist Prompting?
Kurz gesagt: Du gibst der KI eine Anweisung (einen „Prompt"), und je besser diese Anweisung formuliert ist, desto besser das Ergebnis. Die Kunst liegt darin, systematisch statt aus dem Bauch heraus zu formulieren.
Prompt Engineering (auch Prompting) ist ein systematisches und iteratives Verfahren zur Entwicklung und Optimierung von Eingabeaufforderungen (Prompts), bei dem die verwendete Prompting-Technik modifiziert oder gewechselt wird, um Large Language Models (LLMs) effektiv zu steuern und die Qualität der generierten Ausgaben für spezifische Aufgabenstellungen zu maximieren.
2.2 Wie LLMs „wissen" – Pre- und Post-Training
Pre-Training
Die erste Entwicklungsphase, in der ein neuronales Netzwerk auf großen Textmengen des Internets trainiert wird. Die primäre Rechenaufgabe: das statistisch wahrscheinlichste nächste Token (Textbaustein: ein Wort, Wortteil oder Satzzeichen) vorhersagen.
Karpathy (2023) beschreibt LLMs als „verlustbehaftete Komprimierung" des Internets.
Post-Training
Der nachgelagerte Anpassungsprozess, durch den das Basismodell auf die Interaktion als Assistent ausgerichtet wird:
- Supervised Fine-Tuning (SFT): Konditionierung auf Frage-Antwort-Paare
- Reinforcement Learning (RL): Optimierung durch Belohnungsmechanismen
Ziel: Überführung von reiner Textvervollständigung zu instruktionskonformem Antwortverhalten.
2.3 Was ist Context Engineering?
Context Engineering ist die systematische Gestaltung und Optimierung des Context Windows von LLMs, mit dem Ziel, unter begrenzten Ressourcen die Qualität und Zuverlässigkeit der Modellantworten zu maximieren.
Es umfasst Strategien zur Auswahl, Kompression und Anordnung von Informationen im Context Window.
Wie du Context Engineering in der Praxis anwendest, mit konkreter Formel und Beispielen, findest du im Quick Guide: Context Engineering.
2.4 Das Context Window
Das Context Window (auch „Arbeitsgedächtnis" genannt) ist die maximale Anzahl an Token, die ein Modell in einem Durchgang verarbeiten kann. Im Gegensatz zum im LLM repräsentierten Wissen aus dem Training existiert das Context Window nur für die Dauer der Interaktion.
Wichtig: Sowohl Input- als auch Output-Token müssen berücksichtigt werden.
Praxistipp: Context Rot
In langen Gesprächen „verrottet" der Kontext: Frühere Anweisungen werden von neuerem Text verdrängt, die KI vergisst Constraints oder widerspricht sich. Wenn du merkst, dass die Antworten schlechter werden: Starte einen neuen Chat und gib deine wichtigsten Anweisungen frisch ein.
2.5 Risiken bei der KI-Nutzung
Generative KI kann Fachkräften bei vielen Aufgaben helfen: Textentwürfe erstellen, Ideen strukturieren, Informationen zusammenfassen oder Formulierungen in Leichter Sprache vorschlagen. Damit das funktioniert, musst du die Grenzen der Technologie kennen.
Alle generativen KI-Systeme teilen bestimmte strukturelle Risiken. Wer diese kennt, kann ihnen aktiv begegnen.
Halluzinationen: Erfindung von Fakten, Quellen oder Gesetzen. Die KI „lügt" überzeugend.
LLMs erzeugen statistisch plausible Wortfolgen, keine geprüften Fakten. Halluzinationen sind kein Bug, sondern eine strukturelle Eigenschaft: Forschung zeigt, dass sie sich reduzieren, aber nicht eliminieren lassen. Methoden wie quellengestütztes Arbeiten (RAG) und strukturierte Prompts reduzieren das Risiko deutlich (Xu et al., 2024). Besonders gefährlich in der Sozialen Arbeit: erfundene Gesetzesgrundlagen in Berichten, falsche Statistiken in Anträgen, halluzinierte Quellenangaben.
Regel: Jede Faktenangabe einer KI manuell verifizieren.
Sycophancy (Gefälligkeit): Die KI redet dir nach dem Mund, bestätigt falsche Annahmen, statt zu widersprechen.
Aktuelle LLMs werden durch Reinforcement Learning auf hilfreiche Antworten optimiert. Ein Nebeneffekt: Sie tendieren dazu, eher zu bestätigen als zu widersprechen. Antworten, die Nutzer:innen als „hilfreich" bewerten, werden verstärkt. Das führt dazu, dass die KI tendenziell bestätigt, was du hören willst, auch wenn es fachlich falsch ist. In der Sozialen Arbeit kann das bedeuten: Die KI bestätigt eine vorschnelle Einschätzung, statt blinde Flecken aufzuzeigen.
Gegenmaßnahme: Gezielt nach Gegenargumenten fragen („Was spricht gegen meine Einschätzung?").
Bias-Reproduktion: Reproduktion von Stereotypen (Gender, Herkunft, Alter, Klasse) aus den Trainingsdaten.
KI-Modelle lernen aus Milliarden von Texten, die gesellschaftliche Machtverhältnisse und Diskriminierungsstrukturen widerspiegeln. Diese Biases sind nicht sichtbar, sondern in die statistischen Muster eingewoben. In der Sozialen Arbeit besonders relevant: pathologisierende Sprache über bestimmte Gruppen, defizitorientierte Darstellungen, heteronormative Annahmen.
Gegenmaßnahme: Constraints (klare Grenzen: was darf NICHT im Output vorkommen) im Prompt setzen und jeden Output mit dem Output-Check prüfen.
→ Vertiefung: Kapitel 3.5: Bias-Konzepte
Deskilling (Kompetenzverlust): Regelmäßige KI-Nutzung kann dazu führen, dass eigene Fachkompetenzen abnehmen. Gegenmaßnahme: KI als Sparringspartner nutzen, nicht als Ghostwriter. (→ Ausführlich: Contra 1)
Umwelt und Energieverbrauch: KI-Systeme verbrauchen erhebliche Ressourcen, von Trainings-Energie bis zu seltenen Erden.
Das Training großer Sprachmodelle ist sehr energieintensiv; die genauen Zahlen variieren stark je nach Modellgröße, Rechenzentrum und Energiequelle. Auch jede einzelne Anfrage verbraucht Rechenleistung, wenn auch deutlich weniger als das Training. Zusätzlich werden für die Hardware seltene Erden abgebaut, oft unter problematischen Arbeitsbedingungen. Für eine Profession, die sich sozialer Gerechtigkeit verpflichtet, ist das relevant: Die ökologischen und sozialen Kosten der Technologie treffen überproportional den Globalen Süden.
Konsequenz: KI bewusst und gezielt einsetzen, nicht für Aufgaben, die auch ohne KI gut lösbar sind.
Quellen: Strubell, Ganesh & McCallum (2019), Energy and Policy Considerations for Deep Learning in NLP, ACL, DOI: 10.18653/v1/P19-1355; Luccioni, Jernite & Strubell (2024), Power Hungry Processing: Watts Driving the Cost of AI Deployment?, ACM FAccT, DOI: 10.1145/3630106.3658542
Urheberrecht und Copyright: KI-generierte Inhalte können urheberrechtlich geschütztes Material reproduzieren.
LLMs wurden mit Texten, Bildern und Code trainiert, deren Urheber:innen dem häufig nicht zugestimmt haben. Es besteht das Risiko, dass KI-Outputs urheberrechtlich geschützte Formulierungen oder Strukturen enthalten, ohne dass dies erkennbar ist. Die Rechtslage ist in der EU noch nicht abschließend geklärt, der EU AI Act adressiert Transparenzpflichten, aber nicht alle Fragen.
Konsequenz: KI-generierte Texte nicht als Zitat einer externen Quelle ausgeben. Bei der Veröffentlichung von KI-generierten Inhalten transparent machen, dass KI im Prozess eingesetzt wurde.
Rote Linien: Wo generative KI nicht eingesetzt werden darf
- Keine Risikoeinschätzungen (Kindeswohlgefährdung, Suizidalität)
- Keine Diagnosen oder diagnostischen Einordnungen
- Keine Entscheidungen über Hilfegewährung
- Keine ungeprüfte KI-Kommunikation an Klient:innen
- Keine identifizierenden Falldaten in Tools ohne Datenschutzfreigabe
Im Zweifel: Nicht nutzen, Fachberatung oder Supervision einholen.
2.6 Datenschutz und Anonymisierung bei der KI-Nutzung
Grundregel: Keine personenbezogenen Daten eingeben
Unabhängig davon, ob deine Organisation den Einsatz von KI-Tools offiziell geregelt hat oder nicht: Bei jeder Nutzung gelten die DSGVO-Grundsätze:
- Keine Klarnamen von Klient:innen, Kolleg:innen oder Angehörigen eingeben
- Keine Fallnummern, Adressen oder Geburtsdaten verwenden
- Immer anonymisieren bevor du einen Fall mit KI besprichst (z.B. „Person A, 14 Jahre, betreute WG")
- Organisationale Richtlinien beachten: Informiere dich über die KI-Policy deiner Einrichtung
Dies entspricht dem P (Policy Development) im EPIC-Modell: Datenschutz ist nicht optional, sondern professionelle Pflicht.
Datenschutz-Workflow: 5 Schritte bei jeder KI-Nutzung
- Prüfen: Enthält mein Text personenbezogene Daten? Wenn ja → Schritt 2.
- Anonymisieren: Alle Namen, Orte, Geburtsdaten und identifizierenden Details ersetzen (z.B. „Person A, 14 Jahre").
- Prompten: Erst jetzt den anonymisierten Text in das KI-Tool eingeben.
- Prüfen: Output mit Output-Check bewerten: Enthält die Antwort selbst problematische Annahmen?
- Löschen: Chat-Verlauf löschen, wenn sensible Inhalte enthalten waren. Bei Free-Tiers (kostenlose Versionen von KI-Tools): In den Einstellungen prüfen, ob deine Eingaben zum Training verwendet werden, und diese Option ggf. deaktivieren.
Welches Tool-Level für welche Aufgabe?
| Stufe | Beispiel | Ok für… | Nicht ok für… |
|---|---|---|---|
| Free (öffentlich, kostenlos) | ChatGPT Free, Gemini Free | Allgemeine Textarbeit ohne Fallbezug, Ideensammlung | Jegliche personenbezogene oder fallbezogene Daten |
| Paid (Einzellizenz, kostenpflichtig) | ChatGPT Plus, Claude Pro | Wie Free + ggf. bessere Modelle | Sensible Falldaten ohne explizite Prüfung der Datennutzung in den Einstellungen |
| Enterprise/API (mit Auftragsverarbeitungsvertrag) | ChatGPT Enterprise, Claude API | Anonymisierte Falldaten nach Prüfung durch DSB | Nicht-anonymisierte Echtdaten |
| Self-hosted (eigene Infrastruktur) | Mistral auf eigenem Server | Höchste Kontrolle, alle Daten bleiben intern | Erfordert IT-Kompetenz + Wartung |
Transparenz: Wann sagst du, dass KI im Spiel war?
| Situation | Offenlegen? |
|---|---|
| Internes Brainstorming / Ideensammlung | Empfohlen, nicht zwingend |
| Bericht an Kostenträger / Jugendamt | Ja: dokumentieren, dass KI als Hilfsmittel genutzt wurde |
| Material an Klient:innen (Flyer, Info) | Ja: „erstellt mit Unterstützung von KI" |
| Förderantrag | Klären (je nach Fördergeber) |
| Fallnotizen / interne Dokumentation | Empfohlen, für Nachvollziehbarkeit |
Grundregel: Im Zweifel transparent sein. Dokumentiere Tool, Version und Datum.
2.7 Weiterführende Ressourcen
3. Gender, Diversität & Intersektionalität
Digitale Tools und KI halten zunehmend Einzug in die Soziale Arbeit. Sie unterstützen Fachkräfte bei Dokumentation, Kommunikation, Planung oder Informationssuche. Gleichzeitig entstehen neue Risiken: Wenn Gender, Diversität und soziale Ungleichheit nicht mitgedacht werden, können digitale Systeme bestehende Ungleichheiten verstärken, statt sie abzubauen.
Gerade in der Sozialen Arbeit ist das besonders relevant: Hier arbeiten Fachkräfte mit Menschen in komplexen Lebenslagen – und diese Lebenslagen sind immer auch von gesellschaftlichen Machtverhältnissen geprägt.
3.1 Gender – das soziale Geschlecht
Wenn in diesem Leitfaden von Gender gesprochen wird, geht es um das soziale Geschlecht: gesellschaftliche Erwartungen, Rollenbilder und Machtverhältnisse.
Geschlecht ist nicht neutral. Es beeinflusst, welche Chancen Menschen haben, welche Ressourcen sie bekommen und wie viel Anerkennung sie erhalten. Die Beziehungen zwischen den Geschlechtern sind deshalb auch Machtverhältnisse: Durch die Unterscheidung zwischen den Geschlechtern entstehen hierarchische Ungleichheiten.
Quelle: Carstensen, T. & Ganz, K. (2024). Künstliche Intelligenz und Gender – eine Frage diskursiver (Gegen-)Macht? WSI-Mitteilungen. DOI: 10.5771/0342-300X-2024-1-26
Geschlecht wirkt dabei auf mehreren Ebenen gleichzeitig:
- gesellschaftliche Strukturen (z. B. Arbeitsmarkt, Bildungssystem)
- institutionelle Routinen (z. B. Organisationen, Behörden)
- alltägliche Interaktionen
- individuelle Identitätsentwicklung
Geschlecht ist also keine „Eigenschaft von Personen", sondern eine gesellschaftliche Ordnungskategorie. Geschlecht existiert nicht von sich heraus, sondern wird in historischen, kulturellen, sozialen und symbolischen Prozessen hervorgebracht.
Quelle: Mense, L. & Sera, S. (2019). Diversity in der Hochschullehre. In: Angenenet, H. et al. (Hrsg.), Digital Diversity (S. 197–214). Springer VS.
Geschlecht wirkt als grundlegendes Strukturprinzip der Gesellschaft und prägt unter anderem:
- Zugang zu Bildung
- Erwerbsarbeit und Care-Arbeit
- Einkommen und Aufstiegschancen
- Gesundheit und Sicherheit
- politische Teilhabe
- digitale Teilhabe
Ohne Genderperspektive wird der „Mensch" schnell zum impliziten Standard: weiß, männlich, heterosexuell, gesund, mittleren Alters und bildungsnah.
Quelle: de Beauvoir, S. (1949/2011). Das andere Geschlecht (Le Deuxième Sexe).
Für die Praxis bedeutet das: Geschlecht beeinflusst Lebenslagen, Zugänge zu Hilfe, Erfahrungen mit Gewalt, Bildung, Arbeit und Gesundheit.
Geschlecht ist sozial konstruiert und entsprechend wandelbar: Gender existiert nicht von sich heraus, sondern wird historisch, kulturell, sozial und symbolisch in komplexen Prozessen hervorgebracht. Daraus folgt: Geschlecht ist kein statisches Merkmal, sondern ein gesellschaftlicher Tatbestand, der sich kontinuierlich wandelt. Unterschiede zwischen Geschlechtern sind daher Ergebnisse sozialer Prozesse und verändern sich je nach Zeit und kulturellem Kontext.
Quellen: Mense, L. & Sera, S. (2019). Diversity in der Hochschullehre. In: Angenenet, H. et al. (Hrsg.), Digital Diversity (S. 197–214). Springer VS; Milestone, K. & Meyer, A. (2021). Gender and popular culture. 2. Aufl. Polity Press.
Geschlechterrollen sind zugleich mit Machtverhältnissen verbunden. Macht zeigt sich unter anderem in stereotypen Zuschreibungen darüber, wem welche Kompetenzen zugetraut werden.
Quelle: Carstensen, T. & Ganz, K. (2024). Künstliche Intelligenz und Gender – eine Frage diskursiver (Gegen-)Macht? WSI-Mitteilungen. DOI: 10.5771/0342-300X-2024-1-26
Hegemoniale Männlichkeit
Ein zentrales Konzept ist die hegemoniale Männlichkeit nach Connell. Sie beschreibt das gesellschaftlich dominante Männerbild, das mit Eigenschaften wie Weißsein, Heterosexualität, Macht und beruflichem Erfolg verknüpft ist. Dieses Ideal entsteht durch Abgrenzung: Andere Männlichkeiten werden als weniger wertvoll positioniert und tragen gleichzeitig dazu bei, das dominante Männerbild zu stabilisieren.
Quelle: Connell, R. (2014). Der gemachte Mann. Konstruktionen und Krise von Männlichkeiten. 4. Aufl. Springer VS.
3.2 Diversität – Alltag in der Sozialen Arbeit
Diversität beschreibt gesellschaftliche Vielfalt entlang unterschiedlicher sozialer Kategorien, denn Menschen unterscheiden sich in vielen Dimensionen: Alter, Herkunft, Bildung, Behinderung, sexuelle Orientierung, Religion, soziale Lage usw. Diese Vielfalt ist kein „Sonderthema", sondern Kern sozialarbeiterischer Praxis: Die aktive Bearbeitung von Differenz stellt für die Soziale Arbeit einen grundlegenden Auftrag dar, denn Diversity als Konzept von Anerkennung von Vielfalt und Differenz ermöglicht es der Sozialen Arbeit, Differenzverhältnisse ressourcenorientiert in den Blick zu nehmen.
Quelle: Klinger, S., Sackl-Sharif, S., Mayr, A. & Brossmann-Handler, E. (2025). Digitale Soziale Arbeit. Universität Graz. digitalesozialearbeit.github.io
Rahmen für die Soziale Arbeit: Damit ist der normative Rahmen gesetzt: Soziale Arbeit muss Vielfalt nicht nur akzeptieren, sondern aktiv bearbeiten. Diversity zielt dabei nicht nur auf die Bearbeitung, sondern zudem auf die Wertschätzung sozialer Gruppenmerkmale bzw. -identitäten für Organisationen.
Quelle: Walgenbach, K. (2017). Heterogenität – Intersektionalität – Diversity in der Erziehungswissenschaft. 2. Aufl. utb.
Für Fachkräfte bedeutet das: Klient:innen bringen unterschiedliche Lebensrealitäten mit – und benötigen unterschiedliche Zugänge bzw. Arten von Unterstützung. Diversität ist deshalb nicht nur ein Wert, sondern eine professionelle Aufgabe in der Sozialen Arbeit.
3.3 Intersektionalität – warum Kategorien zusammen gedacht werden müssen
Was bedeutet Intersektionalität?
- Soziale Kategorien wie Geschlecht, Herkunft oder Bildung wirken nicht getrennt, sondern überlappen und verstärken sich gegenseitig.
- Der Ansatz entstand aus feministischer Kritik daran, dass Frauen oft als homogene Gruppe gedacht wurden.
- Ziel: mehrere Diskriminierungsformen gleichzeitig betrachten (z. B. Rassismus + Sexismus).
Quelle: Scambor, E. & Kurzmann, C. (2017). Intersektionale Gewaltprävention. In: Stuve, O. et al., Handbuch Intersektionale Gewaltprävention (IGIV). Dissens e.V. Berlin.
Intersektionalität beschreibt damit das Zusammenwirken sozialer Ungleichheiten. Historisch stammt der Ansatz aus dem Black Feminism, der Begriff wurde maßgeblich von Kimberlé Crenshaw geprägt. Intersektionalität beschreibt dabei die Überschneidung mehrerer Kategorien – gedacht am Beispiel des Bilds einer Straßenkreuzung.
In der Praxis zeigt sich: Diskriminierung entsteht selten nur durch eine Kategorie. Häufig wirken mehrere Faktoren gleichzeitig. Macht- und Herrschaftsverhältnisse sowie soziale Ungleichheiten können daher nicht isoliert voneinander gedacht werden, sondern müssen in ihren „Überkreuzungen" analysiert werden.
Quelle: Walgenbach, K. (2017). Heterogenität – Intersektionalität – Diversity in der Erziehungswissenschaft. 2. Aufl. utb.
Wichtig für die Praxis: Es ist nicht möglich, verschiedene Kategorien in einer additiven Weise zusammenzuzählen, um die Situation einer Person zu beschreiben. Intersektionale Zusammenhänge sind veränderbar: Nicht jede Kategorie ist in jeder Situation auf die gleiche Weise wirksam. Intersektionales Denken kann dabei helfen, die komplexen Lebenslagen jedes Menschen besser zu verstehen.
Quelle: Punz, J. (2015). Perspektiven intersektional orientierter Sozialer Arbeit. soziales_kapital, Nr. 13.
3.4 Soziale Arbeit im Spannungsfeld
Soziale Arbeit arbeitet mitten in gesellschaftlichen Machtverhältnissen. Sie unterstützt Menschen – ist aber gleichzeitig Teil von Institutionen und Strukturen. Soziale Arbeit ist daher gleichzeitig:
- Teil gesellschaftlicher Machtverhältnisse
- und Auftraggeberin sozialer Gerechtigkeit.
Quelle: Punz, J. (2015). Perspektiven intersektional orientierter Sozialer Arbeit. soziales_kapital, Nr. 13.
Durch dieses Spannungsfeld, das von sozialen Differenzen und Ungleichheiten geprägt ist, braucht Soziale Arbeit eine reflexive gender- und diversitätssensible Haltung. Intersektionale Perspektiven helfen dabei, denn Intersektionalitätsperspektiven gehen über eine additive Berücksichtigung verschiedener Kategorien hinaus und analysieren deren Zusammenwirken.
Quelle: Riegel, C. & Scharathow, W. (Hrsg.) (2012). Intersektionalität und Soziale Arbeit. VS Verlag.
Für die Praxis bedeutet das: Intersektionale Soziale Arbeit bedeutet, Menschen in ihrer komplexen Vielfalt anzuerkennen, Anerkennungsräume für die spezifischen Lebenssituationen zu schaffen und dadurch Diskriminierung und Gewalt präventiv entgegenzuwirken.
Quelle: Scambor, E. & Kurzmann, C. (2017). Intersektionale Gewaltprävention. In: Stuve, O. et al., Handbuch Intersektionale Gewaltprävention (IGIV). Dissens e.V. Berlin.
Gender- und diversitätssensible Arbeit ist auch Gewaltprävention
Diskriminierung und Gewalt hängen eng zusammen. Wer systematisch ausgeschlossen oder abgewertet wird, erlebt häufiger Gewalt. Intersektionale Perspektiven sind zentral für Gewaltprävention, denn soziale Kategorien sind stark mit Dominanzverhältnissen verwoben und keinesfalls neutral.
Intersektionale Gewaltprävention bedeutet:
- Dominanz abbauen
- marginalisierte Gruppen stärken
- gesellschaftliche Verhältnisse verändern
Quelle: Stuve, O. et al. (2011). Handbuch Intersektionale Gewaltprävention (IGIV). Dissens e.V. Berlin.
Für die Praxis heißt das: Gender- und diversitätssensible Arbeit ist immer auch Gewaltprävention.
3.5 Technik ist nicht neutral
Technik entsteht nicht im luftleeren Raum. Digitale Tools wirken oft objektiv – sind es aber nicht, denn Technik ist nicht neutral. Technik wird von Menschen entwickelt und spiegelt entsprechend auch gesellschaftliche Verhältnisse wider. So sind beispielsweise Sexismus, Rassismus und klassenbasierte Diskriminierung bereits in technische Systeme eingeschrieben. In der Technikforschung spricht man daher von gendered substructures.
Quellen: Carstensen, T. & Ganz, K. (2023). Vom Algorithmus diskriminiert? Zur Aushandlung von Gender in Diskursen über Künstliche Intelligenz und Arbeit. Working Paper Nr. 274. Hans-Böckler-Stiftung; Horwath, I. (2022). Algorithmen, KI und soziale Diskriminierung. In: Schnegg, K. et al. (Hrsg.), Inter- und multidisziplinäre Perspektiven der Geschlechterforschung. innsbruck university press.
Gender Data Gap
Der Gender Data Gap beschreibt fehlende Daten über Frauen und marginalisierte Gruppen, denn trotz großer Datenmengen fehlen vielfach valide Daten über Frauen und verschiedene Minderheiten.
Quelle: Horwath, I. (2022). Algorithmen, KI und soziale Diskriminierung. In: Schnegg, K. et al. (Hrsg.), Inter- und multidisziplinäre Perspektiven der Geschlechterforschung. innsbruck university press.
Auch die KI arbeitet mit Daten. Wenn bestimmte Gruppen in Daten fehlen oder schlecht erfasst sind, entstehen Verzerrungen (siehe Kapitel 3.7 Bias).
- Sprachsysteme erkennen Männerstimmen besser
- Assistenzsysteme haben oft weibliche Stimmen (Service = weiblich)
- Gesichtserkennung erkennt Frauen of Color schlechter
Quelle: Carstensen, T. & Ganz, K. (2024). Künstliche Intelligenz und Gender – eine Frage diskursiver (Gegen-)Macht? WSI-Mitteilungen. DOI: 10.5771/0342-300X-2024-1-26
Medizin: Medikamente werden überwiegend an Männern getestet. Symptome von Herzinfarkten bei Frauen werden schlechter erkannt.
Verkehr: Crash-Test-Dummies basieren auf männlichen Körpern. Frauen haben ein deutlich höheres Verletzungsrisiko bei Autounfällen.
Stadtplanung: Öffentliche Räume orientieren sich an männlichen Mobilitätsmustern.
Quelle: Criado-Perez, C. (2020). Unsichtbare Frauen. Wie eine von Daten beherrschte Welt die Hälfte der Bevölkerung ignoriert. Btb Verlag.
Digitale Technik und Assistenzsoftware: Sprachsysteme erkennen Männerstimmen besser. Assistenzsysteme haben oft weibliche Stimmen (weil man Service mit einer stereotypen Frauenrolle verknüpft). Gesichtserkennung erkennt Frauen of Color schlechter.
Quelle: Carstensen, T. & Ganz, K. (2024). Künstliche Intelligenz und Gender – eine Frage diskursiver (Gegen-)Macht? WSI-Mitteilungen. DOI: 10.5771/0342-300X-2024-1-26
Geschlechtsspezifische Prägungen in IT und Technikentwicklung: In der Praxis wird Technik noch immer stark mit Männlichkeit verbunden. Der hohe Männeranteil in technischen Berufen führt dazu, dass häufig ein männlicher Standard entsteht. So hatten auf der Spielemesse E3 im Jahr 2016 nur 3,3 % der präsentierten Spiele weibliche Protagonistinnen. Auch frühe Spracherkennungssysteme erkannten zunächst überwiegend männliche Stimmen. Bei Sprachassistenten wie Siri oder Alexa werden häufig weibliche Stimmen als Standard eingesetzt, insbesondere für unterstützende und dienende Funktionen. Geschlechterstereotype werden in der Robotik bewusst genutzt, um die Akzeptanz zu erhöhen – und dadurch gleichzeitig unreflektiert reproduziert.
Quellen: Criado-Perez, C. (2020). Unsichtbare Frauen. Btb Verlag; Bath, C. (2009). Searching for methodology: Feminist technology design in computer science; Enders, J. & Groschke, A. (2019). Geschlechterverhältnisse im Digitalen. In: Höfner, A. & Frick, V. (Hrsg.), Was Bits und Bäume verbindet (S. 94–97). Oekom.
Gender Data Gap in der Sozialen Arbeit – mögliche Risiken:
- KI-Systeme orientieren sich an „Standardklient:innen"
- Spezifische Lebenslagen werden übersehen
- Mehrfachdiskriminierung wird nicht erkannt
Beispiel: Ein KI-Tool erkennt Risikofaktoren für Gewalt – aber berücksichtigt keine Rassismus- oder Diskriminierungserfahrungen und keine Genderdimension. → Risiko falscher Einschätzungen.
Die Strukturen digitaler Technologien sind stark von bestehenden Identitätskategorien wie Geschlecht, „Race" und Klasse geprägt. Dadurch bleibt die digitale Welt in vieler Hinsicht ein Abbild der analogen Machtverhältnisse. Auch die Einführung neuer Technologien sowie ihre Aneignung und Nutzung stehen in engem Zusammenhang mit Macht- und Dominanzverhältnissen. Diese können bestehende soziale Ungleichheiten nicht nur fortschreiben, sondern auch neue Ungleichheiten hervorbringen.
Quellen: Enders, J. & Groschke, A. (2019). Geschlechterverhältnisse im Digitalen. In: Höfner, A. & Frick, V. (Hrsg.), Was Bits und Bäume verbindet (S. 94–97). Oekom; Groen, M. & Tillmann, A. (2019). Let's play (gender)? In: Angenenet, H. et al. (Hrsg.), Digital Diversity (S. 143–159). Springer VS.
3.6 KI, Gender & Diversität
KI reproduziert gesellschaftliche Muster, denn KI lernt aus vorhandenen Daten. Dadurch werden bestehende gesellschaftliche Muster verstärkt. Auch ein Algorithmus kann lediglich eine Reproduktion von bereits vorhandenem Kontext herstellen, denn Trainingsdaten enthalten kulturelle Muster und reproduzieren Geschlechterhierarchien.
Quellen: Linnemann, G. A., Löhe, J. & Rottkemper, B. (2023). Bedeutung von KI in der Sozialen Arbeit. Soziale Passagen, 15, 197–211. DOI: 10.1007/s12592-023-00455-7; Carstensen, T. & Ganz, K. (2024). Künstliche Intelligenz und Gender – eine Frage diskursiver (Gegen-)Macht? WSI-Mitteilungen. DOI: 10.5771/0342-300X-2024-1-26
Beispiele:
- Übersetzungen reproduzieren Rollenbilder („Arzt" vs. „Krankenschwester")
- Bewerbungsalgorithmen bevorzugen Männer
- Entscheidungssoftware wirkt neutral – ist es aber nicht
„Die Gefahr besteht, dass Entscheidungsmacht zunehmend auf Software übertragen wird."
Quelle: Carstensen, T. & Ganz, K. (2024). Künstliche Intelligenz und Gender – eine Frage diskursiver (Gegen-)Macht? WSI-Mitteilungen. DOI: 10.5771/0342-300X-2024-1-26
Was bedeutet das für die Praxis der Sozialen Arbeit?
KI wird zunehmend relevant für Soziale Arbeit und kann unterstützen – aber nur, wenn sie kritisch genutzt wird. Wichtig ist dabei ein gender- und diversitätssensibler, intersektionaler Ansatz als Gradmesser für die Qualität der eigenen Arbeit.
Quelle: Carstensen, T. & Ganz, K. (2024). Künstliche Intelligenz und Gender – eine Frage diskursiver (Gegen-)Macht? WSI-Mitteilungen. DOI: 10.5771/0342-300X-2024-1-26
3.7 Bias-Konzepte
Bias bei Menschen (Unconscious Bias)
Bias bedeutet „Verzerrung". Bei Menschen bezeichnet Bias – meist kognitive Biases – systematische Abweichungen von rationalem Denken, die Urteile, Wahrnehmung oder Entscheidungen verzerren. Diese entstehen oft unbewusst durch mentale Abkürzungen (Heuristiken), begrenzte Informationsverarbeitung oder emotionale Einflüsse.
Unconscious Bias bezeichnet kognitive Prozesse, bei denen frühere Erfahrungen, soziale Kategorien und kulturell vermittelte Stereotype Urteile beeinflussen, ohne dass sich die handelnden Personen dessen bewusst sind.
Quellen: Greenwald, A. G. & Lai, C. K. (2020), Implicit Social Cognition, Annual Review of Psychology, DOI: 10.1146/annurev-psych-010419-050837; Kahneman, D., Slovic, P. & Tversky, A. (1982), Judgment under Uncertainty: Heuristics and Biases, Cambridge University Press
Im Arbeitsalltag der Sozialen Arbeit werden Entscheidungen oft unter Zeitdruck, hoher Verantwortung und emotionaler Belastung getroffen. Diese Rahmenbedingungen beeinflussen, wie viele kognitive Ressourcen für die Prüfung von KI-Outputs verfügbar sind und wie motiviert wir sind, sie gründlich zu prüfen. Wenn ein Thema als wichtig erlebt wird und ausreichend Zeit und Energie vorhanden sind, wird sorgfältiger geprüft. Fehlen diese Voraussetzungen, werden eher bewährte Denkabkürzungen genutzt.
Gerade dann gewinnen äußere Hinweise, die nicht im KI-Output selbst liegen, an Bedeutung. Dazu zählen etwa die wahrgenommene Kompetenz eines KI-Systems, Erfahrungen von Kolleg:innen oder die offizielle Einführung durch die Organisation. Solche Orientierungshilfen sind im komplexen Arbeitsalltag oft hilfreich, können aber auch dazu führen, dass KI-Ausgaben aufgrund von augenscheinlicher Plausibilität oder formaler Legitimation übernommen werden, statt sie im konkreten Fall systematisch zu überprüfen.
Für die Soziale Arbeit bedeutet das, dass der Einsatz von KI bewusst reflektiert werden sollte, nicht weil Fachkräfte durch die Nutzung von KI-Systemen falsch handeln, sondern weil Arbeitsbedingungen häufig die Nutzung von Denkabkürzungen erforderlich machen. Professionell ist daher, sich immer wieder zu fragen, ob die aktuellen Umstände eine unkritische Übernahme von KI-Ausgaben begünstigen und ob in diesem Fall eine zusätzliche Prüfung nötig ist.
Quellen: Petty, R. E. & Cacioppo, J. T. (1986). Communication and Persuasion. Springer. DOI: 10.1007/978-1-4612-4964-1; Chaiken, S. (1987). The heuristic model of persuasion. In: Zanna, M. P., Olson, J. M. & Herman, C. P. (Eds.), Social influence: The Ontario symposium (Vol. 5, S. 3–39). Lawrence Erlbaum Associates | Text: Arndt
Ressourcen zum Thema Unconscious Bias
- Imperial College London – Unconscious Bias Training (45 Min.)
- Harvard Project Implicit – Implicit Association Test (IAT)
- The Royal Society – Understanding Unconscious Bias (Video, 3 Min.)
Bias bei Maschinen (Algorithmischer Bias)
Bei Maschinen und KI bezeichnet Bias systematische Verzerrungen oder Voreingenommenheiten in Daten, Algorithmen oder Ergebnissen, die dazu führen, dass bestimmte Personen, Gruppen oder Merkmale ungerecht bevorzugt oder benachteiligt werden.
Was haben Biases mit Sozialer Arbeit zu tun?
Biases beeinflussen professionelles Handeln in der Sozialen Arbeit, weil sie Wahrnehmung, Deutung und Entscheidung beeinflussen – was zu ungleicher Behandlung bei Beratung, Diagnostik, Fallverstehen und Hilfeplanung führen kann.
In der fachlichen Debatte wird betont, dass soziale Dienste und digitale Hilfsmittel (z.B. KI-Tools) aktiv reflektiert werden müssen, um ungleiche Ergebnisse oder Diskriminierungen zu vermeiden.
Quelle: Späte, J. et al. (Hrsg.) (2025). #GesellschaftBilden im Digitalzeitalter. Waxmann. DOI: 10.31244/9783830999973
Was haben Biases mit Gender/Diversität/Intersektionalität zu tun?
Biases sind eng mit gesellschaftlichen Normen und Machtstrukturen verknüpft:
- Gender Bias: Stereotype Verzerrungen, die z.B. Frauen oder nicht-binäre Personen benachteiligen
- Diversität: Verzerrungen beziehen sich auch auf Ethnizität, Klasse oder Alter
- Intersektionalität: Multiple Identitätsmerkmale überlagern sich; Biases können diese Mehrfachbelastungen unsichtbar machen
Algorithmische Systeme spiegeln gesellschaftliche Stereotype wider und können Biases verstärken (z.B. in Berufsdarstellungen oder Entscheidungssituationen).
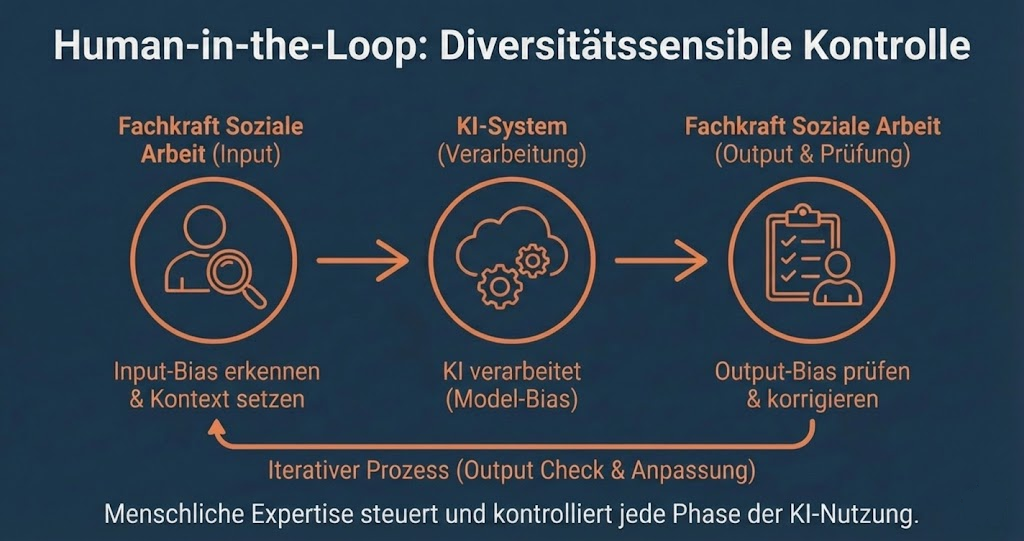
Der Einfluss von Biases beim Prompting
Beim Prompting können Biases auf mehreren Ebenen wirken:
-
Input-Bias: Die promptende Person formt die Anfrage mit eigenen Annahmen oder stereotypen Formulierungen.
-
Model Bias: KI-Modelle wurden auf Textdaten trainiert, die gesellschaftliche Stereotype reproduzieren.
-
Output Bias: KI-Antworten können diskriminierende oder stereotype Muster verstärken.
Bias-Management-Strategien für besseres Prompting
- Reflexion & Metaprompting: Sich bewusst machen, welche sozialen Annahmen ein Prompt enthalten kann.
- Diversitätsorientierte Instruktionen: Soziale Gruppen und intersektionale Aspekte explizit nennen.
- Fairness-Abfragen: KI um kritische Reflexion möglicher Biases im Output bitten.
- Iteratives Prompting: Prompt mehrfach reformulieren und Ergebnisse vergleichen.
Weiterführende Literatur zu Bias & KI
- Späte et al. (2025): #GesellschaftBilden im Digitalzeitalter (Open Access)
- Ho et al. (2025): Gender biases within AI and ChatGPT
- Shrestha & Das (2022): Exploring gender biases in ML and AI academic research
Die dargestellten Zusammenhänge zeigen: Gender-, diversitäts- und intersektionalitätssensible Perspektiven sind kein Nice-to-have, sondern Voraussetzung für verantwortungsvolle KI-Nutzung in der Sozialen Arbeit.
Im folgenden Kapitel werden deshalb konkrete Anwendungsbeispiele vorgestellt, die zeigen, wie diese Perspektiven in der täglichen Arbeit umgesetzt werden können.
4. Anwendungsbeispiele
4.1 Übersicht: Tätigkeitsfelder für KI-Einsatz
Berichtswesen & Administration
- Verfassen/Verbessern von (Jahres-)berichten
- Protokolle erstellen
- Förderanträge formulieren
EPIC-Fokus: P (Policy), Beispiel 4.4
Contenterstellung
- Webcontent erstellen
- Werbeflyer gestalten
- Pädagogische Konzepte
- Bilder und Videos
EPIC-Fokus: E (Ethics) + C (Community), Beispiel 4.2
Fallarbeit
- Fallreflexion
- Anamnese-Vorbereitung
- Hilfeplanung
EPIC-Fokus: E (Ethics), Beispiel 4.3
Direkte Arbeit
- Verhaltensbeobachtungen diskutieren
- Beratungsvorbereitung
- Offene Jugendarbeit
EPIC-Fokus: E (Ethics) + I (Intersectoral), Beispiel 4.5
4.2 Beispiel: Contenterstellung, Gaming Flyer
Szenario: Das Jugendzentrum Sonnenberg (fiktiv) plant ein Gaming-Event. Das Team ist überwiegend männlich, die Stammbesucher:innen sind überwiegend männlich gelesene Jugendliche. Ziel: Ein Flyer, der alle Geschlechter anspricht und auch weiblich gelesene sowie nicht-binäre Jugendliche erreicht.
Dieses Beispiel zeigt den vollständigen iterativen Prompting-Prozess in 6 Schritten: von der ersten Idee bis zum fertigen Ergebnis. Hinweis für die Praxis: Im Arbeitsalltag hast du selten Zeit für 6 Runden. Meistens reichen 2–3 gezielte Schleifen. Wir zeigen hier den ausführlichen Weg, damit du die Wirkung der Werkzeuge im Detail siehst.
Kontext geben, KI fragen lassen
Die KI fragte nach: Eventname, Datum, Zielgruppe, Spiele/Konsolen, Highlights, Eintritt, Anmeldung, Logo, Design-Präferenzen, Format.
Diversitätsziele als Constraint setzen
Das Team lieferte die Basisinfos: „Game On! – Zocken im JuZe", Samstag 15.3., 14-20 Uhr, Zielgruppe 12-14 Jahre, FIFA-Turnier, 3 PS5 + 2 Switch + PCs, freier Eintritt. Dann der entscheidende Zusatz:
KI erkennt Gender-Kodierungen
Die KI identifizierte drei Probleme:
| Problem | Warum problematisch | Vorschlag |
|---|---|---|
| FIFA-Turnier | Kann männlich konnotiert wirken, signalisiert „nicht für mich" | Mario Kart (universeller), Koop-Stationen (It Takes Two, Overcooked) |
| „Zocken" im Titel | Kann je nach Kontext männlich konnotiert wirken | „Spielenachmittag", „Level Up!", „Let's Play" |
| Design (antizipiert) | Dunkle/Neon „Hardcore Gamer"-Ästhetik schließt aus | Bunt, einladend, verschiedene Controller-Typen |
KI-Output: Weiterführende Empfehlungen
Neben der Gender-Analyse lieferte die KI konkrete Umsetzungsvorschläge:
- Spielauswahl diversifizieren: It Takes Two, Overcooked, Stardew Valley, Just Dance (Koop- und kreative Spiele neben kompetitiven)
- Explizite Willkommensbotschaft: „Alle willkommen, egal ob Gaming-Profi oder Neuling" auf dem Flyer
- Botschafter:innen einsetzen: Weiblich gelesene Jugendliche als Event-Botschafterinnen gewinnen
- Teambesetzung prüfen: Gemischtgeschlechtliches Betreuungsteam sichtbar machen
- Hausregeln kommunizieren: „Respektvoller Umgang" als sichtbare Regel, nicht nur als Annahme
Nicht alles davon ist umsetzbar oder sinnvoll, aber die KI liefert einen breiten Möglichkeitsraum, aus dem die Fachkraft auswählt.
Mensch entscheidet
Fachkraft erkennt, was KI nicht sieht
Die KI generierte einen Flyer mit „Mario Kart Turnier" als Highlight. Das Team erkannte: „Turnier" ist kompetitiv, Gewinnen/Verlieren kann in diesem Kontext männlich konnotiert wirken. Auch nach dem Wechsel von FIFA zu Mario Kart blieb das kompetitive Framing bestehen.
Ergebnis: Koop-Gaming wurde zum visuellen Zentrum. „Team-Turnier" ersetzte das Einzelturnier. Spiele: It Takes Two, Overcooked, Mario Kart Teams, Minecraft.
Feinschliff: Der „Cringe-Test"
Die KI schlug als Slogan vor: „Gemeinsam spielen, gemeinsam Spaß haben!"
Das Team strich den Slogan. Zu pädagogisch, 12-14-Jährige würden das als „cringe" empfinden.
Output-Check: Angewandt auf den fertigen Flyer
Bevor der Flyer gedruckt wird, wenden wir die Output-Check-Checkliste auf das Endergebnis an:
| Prüfkriterium | Befund |
|---|---|
| Fühlt sich der Text „von oben herab" an? | Nein. Einladung auf Augenhöhe, Du-Ansprache. Aber: Slogan „Gemeinsam spielen, gemeinsam Spaß haben!" war zu pädagogisch → gestrichen (Schritt 6). |
| Werden FLINTA* Personen (Frauen, Lesben, inter*, nicht-binäre, trans* und agender Personen) unsichtbar gemacht oder stereotyp dargestellt? | Bewusst adressiert: Koop-Fokus statt Wettbewerb, diverse Spielauswahl, „Alle willkommen"-Messaging. |
| Werden bestimmte Gruppen als „Problemgruppen" markiert? | Nein, es geht um Einladung, nicht um Defizite. Kein „Mädchen trauen sich nicht"-Framing. |
| Ist die Sprache pathologisierend oder defizitorientiert? | Nein, ressourcenorientiert. Jugendliche werden als kompetente Akteur:innen angesprochen. |
| Werden Quellen genannt? Existieren diese wirklich? | Nicht relevant für Flyer-Text. Aber: Bei KI-generierten Bildern prüfen, ob Logos/Marken halluziniert wurden (z.B. Nintendo-Logo ohne Lizenz). |
| Würde ich diesen Flyer so an Jugendliche weitergeben? | Fast. Offene Frage bleibt: Wurde die Zielgruppe selbst gefragt? Das Event wurde von Erwachsenen für Jugendliche geplant. Ein Feedback-Loop mit Jugendlichen fehlt noch. |
Ergebnis: Der fertige Flyer-Entwurf
Nach 6 Iterationsschritten und Output-Check entstand folgendes Konzept:
- Eventname: „Game On! – Spielenachmittag im JuZe"
- Zentrales Framing: Gemeinsam spielen (Koop), nicht Gewinnen/Verlieren (Turnier)
- Spiele: Mario Kart Teams, It Takes Two, Overcooked, Minecraft
- Messaging: „Alle willkommen, egal ob Gaming-Profi oder Neuling"
- Design: Einladende Farbpalette (statt dunkler Gamer-Ästhetik), verschiedene Controller-Typen abgebildet
- Format: A4-Poster + Instagram-Quadrat
Nächster Schritt im echten Prozess: Feedback von Jugendlichen einholen, bevor der Flyer gedruckt wird.
Free vs. Pro: Du bekommst, wofür du zahlst
Derselbe Prompt wurde sowohl in der kostenlosen als auch in der bezahlten Version eines KI-Bildgenerators ausgeführt:

Free Version: „Spielenachant itag"

Pro Version: „Spielenachmittag" (korrekt)
Der Qualitätsunterschied ist nicht marginal, er ist der Unterschied zwischen brauchbar und unbrauchbar. Für den professionellen Einsatz in der Sozialen Arbeit lohnt sich die Investition in bezahlte Versionen.
4.3 Beispiel: Betreuung in einer WG
Szenario: Ein Sozialarbeiter in einer betreuten Wohngruppe beobachtet aggressives Verhalten bei einer 14-jährigen Bewohnerin. Nachdem er sie fragte, wie es ihr heute geht, schreit sie ihn an und wirft einen Schlüssel zu Boden. Da dieses Verhalten für diese Bewohnerin untypisch ist, sucht er Unterstützung bei einem generativen KI-Tool.
„Ein Klient zeigt aggressives Verhalten. Was soll ich tun?"
Problem: Kein Kontext, keine Constraints. Dazu „ein Klient" (generisch maskulin), obwohl es um eine 14-jährige Bewohnerin geht. Geschlecht, Alter und Situation sind relevanter Kontext, der hier komplett fehlt. Die KI wird vermutlich generische, möglicherweise pathologisierende Ratschläge geben.
Kontext: Ich bin systemischer Sozialarbeiter in einer betreuten WG. Eine 14-jährige Bewohnerin zeigt untypisch aggressives Verhalten; sie hat heute geschrien und einen Schlüssel geworfen.
Aufgabe: Hilf mir, mögliche Ursachen und Handlungsansätze zu reflektieren.
Constraints: Keine pathologisierende Sprache, ressourcenorientiert, traumasensibel, Beziehungserhalt priorisieren
Format: Stichpunkte, max. 5 Handlungsansätze
KI-Output: 5 Handlungsansätze
- Sicheren Rahmen schaffen: Ruhigen Moment abwarten, Rückzugsraum anbieten, Präsenz signalisieren ohne zu drängen. („Ich bin da, wenn du reden willst.")
- Systemisch denken: Was hat sich im Umfeld verändert? Schulische Belastung, familiäre Situation, Peergroup-Dynamiken? Das Verhalten als Signal lesen, nicht als Eigenschaft.
- Kollegiale Rücksprache: Haben andere Betreuer:innen ähnliche Beobachtungen gemacht? Dokumentierte Muster prüfen, um das Verhalten im Zeitverlauf einzuordnen.
- Impulskontrolle stärken: Übungen zur Emotionsregulation anbieten, z.B. Atemtechniken oder Journaling. So lernt die Bewohnerin, starke Emotionen besser zu kanalisieren.
- Beziehungsangebot erneuern: Niedrigschwellige gemeinsame Aktivität vorschlagen, die nicht an den Vorfall gebunden ist, z.B. gemeinsam kochen oder spazieren gehen.
Output-Check (Auswahl): Was fällt auf?
Für dieses Szenario sind 4 von 7 Kriterien besonders relevant (Adultismus, Pathologisierung, Gruppenmarkierung, Verwendbarkeit):
| Prüfkriterium | Befund |
|---|---|
| Fühlt sich der Text „von oben herab" an? | Nein, respektvoller Ton. Aber: Punkt 4 hat ein subtiles „Erwachsene wissen, was gut für dich ist"-Framing. |
| Ist die Sprache pathologisierend oder defizitorientiert? | Ja, Punkt 4! „Impulskontrolle stärken" rahmt das Verhalten als Defizit, das repariert werden muss. „Emotionen besser kanalisieren" impliziert, dass die Bewohnerin etwas falsch macht, statt zu fragen, was sie damit ausdrückt. |
| Werden bestimmte Gruppen als „Problemgruppen" markiert? | Nein. Das Verhalten wird als Signal gelesen, nicht als Identitätsmerkmal. |
| Würde ich diesen Text so verwenden? | Punkte 1, 2, 3, 5: ja, wertvolle Reflexionsanstöße. Punkt 4: nein, muss umformuliert werden. |
Korrektur von Punkt 4: Statt „Impulskontrolle stärken" besser: „Ausdrucksmöglichkeiten erkunden: Welche anderen Wege hat die Bewohnerin, um das auszudrücken, was sie gerade erlebt? Gibt es kreative, körperliche oder sprachliche Kanäle, die sie selbst bevorzugt?"
4.4 Beispiel: Berichte und Anträge
Szenario: Eine Sozialarbeiterin in einer stationären Kinder- und Jugendhilfeeinrichtung muss einen Entwicklungsbericht für die halbjährliche Hilfeplankonferenz schreiben. Sie hat Beobachtungsnotizen aus dem Betreuungsalltag und möchte KI nutzen, um diese in einen strukturierten Bericht zu überführen.
Zentrales Lernziel dieses Beispiels: Anonymisierung in der Praxis. Wie bereite ich Falldaten auf, bevor sie in ein KI-Tool eingegeben werden?
Stopp! Erst anonymisieren. (EPIC: P, Policy)
Keine echten Namen oder Falldaten in kostenlose KI-Tools eingeben! Das ist in der Regel ein Datenschutzverstoß, auch dann, wenn du „nur schnell etwas nachschauen" willst. Bevor irgendein Text in ein KI-Tool eingegeben wird, müssen alle personenbezogenen Daten entfernt werden (siehe Kapitel 2.6: Datenschutz und Anonymisierung). Hier ein konkretes Beispiel:
„Sara Meier (geb. 14.05.2011), Bewohnerin seit Sept. 2024, WG Ahornweg 7, Graz. Besuch bei ihrer Mutter Nadia am Wochenende verlief schlecht, Sara kam aufgelöst zurück. Lehrerin Fr. Koller (NMS Andritz) meldete Rückzug im Unterricht. Kinderpsychologin Dr. Berger empfiehlt Traumatherapie."
„Person A, 14 Jahre, weiblich, Bewohnerin einer betreuten WG seit ca. 6 Monaten. Wochenendbesuch beim Elternteil verlief belastend. Person A kam emotional aufgelöst zurück. Schule meldete Rückzug im Unterricht. Externe Fachkraft empfiehlt traumatherapeutische Anbindung."
Prompt: Entwicklungsbericht strukturieren
Aufgabe: Hilf mir, die folgenden anonymisierten Beobachtungsnotizen in einen strukturierten Entwicklungsbericht zu überführen.
Fallkontext: Person A, 14 Jahre, weiblich, lebt seit 6 Monaten in einer betreuten WG. Die vorherige Hilfeplanung hatte folgende Ziele formuliert: (1) Stabilisierung der schulischen Situation, (2) Aufbau tragfähiger Beziehungen in der WG, (3) Klärung der Beziehung zum Herkunftssystem.
Beobachtungen der letzten 6 Monate:
– Schulbesuch: Anfangs regelmäßig, seit ca. 6 Wochen zunehmender Rückzug. Schule meldet sinkende Beteiligung.
– WG-Alltag: Gute Integration in die Gruppe in den ersten Monaten. Seit dem belastenden Wochenendbesuch beim Elternteil vor 3 Wochen zunehmend gereizt und zurückgezogen.
– Freizeitverhalten: Nimmt am wöchentlichen Kochprojekt teil, hat dort Freundschaft mit einer Mitbewohnerin aufgebaut.
– Externe Anbindung: Externe Fachkraft empfiehlt traumatherapeutische Anbindung.
Constraints: Ressourcenorientierte Sprache, keine pathologisierenden Formulierungen, Fortschritte klar benennen, Entwicklungsbedarfe als offene Fragen formulieren (nicht als Defizite).
Format: Strukturiert nach Bereichen (Schulische Entwicklung, Soziale Beziehungen, Emotionale Entwicklung, Herkunftssystem, Empfehlungen). Fachlicher Ton, max. 1 Seite."
KI-Output: Entwicklungsbericht (Entwurf)
Schulische Entwicklung: Person A zeigte in den ersten Monaten regelmäßigen Schulbesuch und stabile Beteiligung. Seit etwa sechs Wochen ist ein Rückzug erkennbar. Die Schule meldet sinkende Beteiligung am Unterricht. Der zeitliche Zusammenhang mit dem belastenden Elternbesuch legt nahe, dass die schulische Veränderung im Kontext der familiären Dynamik zu verstehen ist. Die anfänglich positive Entwicklung zeigt, dass Person A die Ressourcen für einen gelingenden Schulalltag grundsätzlich mitbringt.
Soziale Beziehungen: Person A hat sich in den ersten Monaten gut in die WG-Gruppe integriert. Im Kochprojekt hat sich eine Freundschaft mit einer Mitbewohnerin entwickelt, die auf Beziehungsfähigkeit und Offenheit für neue Kontakte hinweist. Seit dem belastenden Elternbesuch zeigt sich vermehrte Gereiztheit im Gruppenalltag.
Emotionale Entwicklung: Die emotionale Stabilität, die Person A in den ersten Monaten aufgebaut hatte, ist durch den belastenden Kontakt mit dem Herkunftssystem erschüttert worden. Person A zeigt Schwierigkeiten, ihre Emotionen altersadäquat zu regulieren, was sich in Rückzug und Gereiztheit äußert.
Herkunftssystem: Der Wochenendbesuch beim Elternteil verlief belastend. Die nachfolgende Destabilisierung macht deutlich, dass die Klärung der Beziehung zum Herkunftssystem eine zentrale Entwicklungsaufgabe bleibt.
Empfehlungen: (1) Traumatherapeutische Anbindung einleiten, wie von externer Fachkraft empfohlen. (2) Schulische Situation engmaschig begleiten und Kontakt zur Schule intensivieren. (3) Das Kochprojekt als stabilisierende Ressource beibehalten und ausbauen. (4) Begleitete Kontaktgestaltung mit dem Herkunftssystem prüfen.
Output-Check (Auswahl): Was fällt auf?
Für diesen Bericht sind 4 von 7 Kriterien besonders relevant (Pathologisierung, Tonfall, Quellenprüfung, Verwendbarkeit):
| Prüfkriterium | Befund |
|---|---|
| Ist die Sprache pathologisierend oder defizitorientiert? | Ja, bei „Emotionale Entwicklung"! „Schwierigkeiten, ihre Emotionen altersadäquat zu regulieren" ist pathologisierend. Besser: „Die emotionale Belastung durch den Elternbesuch zeigt sich aktuell in Rückzug und Gereiztheit." Beschreibt dasselbe, ohne ein Defizit zu unterstellen. |
| Fühlt sich der Text „von oben herab" an? | Nein. Respektvoller, fachlicher Ton. Ressourcen werden sichtbar gemacht (Kochprojekt, Beziehungsfähigkeit). |
| Werden Quellen/Fakten korrekt wiedergegeben? | Vorsicht: Die KI hat den „zeitlichen Zusammenhang" zwischen Schulrückzug und Elternbesuch als Kausalität interpretiert. Das steht so nicht in den Notizen. Die Fachkraft muss entscheiden, ob diese Verknüpfung fachlich begründet ist. |
| Würde ich diesen Bericht so einreichen? | Als Entwurf brauchbar, aber: (1) pathologisierende Stelle korrigieren, (2) kausale Verknüpfung prüfen, (3) vor der Einreichung die echten Namen, Daten und Orte wieder einfügen und den Bericht finalisieren. |
Praxistipp: Word-Vorlagen nutzen
Viele Einrichtungen haben Vorlagen für Entwicklungsberichte. So nutzt du diese mit KI:
- Vorlage hochladen: Lade die leere (!) Word-Vorlage in den Chat hoch und schreib: „Das ist unsere Vorlage für Entwicklungsberichte. Bitte verwende diese Struktur für den folgenden Bericht."
- Anonymisierte Notizen liefern: Gib deine Beobachtungsnotizen in anonymisierter Form ein (wie oben gezeigt).
- Output rückübertragen: Kopiere den KI-Output zurück in die Word-Vorlage, füge die echten Daten wieder ein und finalisiere den Bericht.
Wichtig: Lade niemals eine bereits ausgefüllte Vorlage mit echten Falldaten hoch. Immer erst anonymisieren, dann eingeben.
4.5 Beispiel: Direkte Arbeit, Beratungsvorbereitung
Szenario: Eine Sozialarbeiterin in der offenen Jugendarbeit bemerkt, dass ein 12-jähriger Stammbesucher seit Wochen in schmutziger Kleidung und ohne Jause ins Jugendzentrum kommt. Ein Gespräch mit den Eltern steht an. Sie möchte es so vorbereiten, dass es unterstützend wirkt und nicht vorwurfsvoll.
Zentrales Lernziel: KI als Vorbereitungshilfe, nicht als Ersatz. Wo KI aufhört und professionelle Beziehungsarbeit anfängt.
Prompt: Elterngespräch vorbereiten
Aufgabe: Ich bereite ein Elterngespräch vor und möchte die Eltern unterstützend ansprechen, ohne vorwurfsvoll zu wirken.
Constraints: Keine Schuldzuweisungen, ressourcenorientiert. Unterstelle den Eltern keine Absicht, sondern Überforderung. Eltern als Partner:innen sehen, nicht als Gegner:innen. Ziel ist Kooperation, nicht Belehrung. Keine vorschnelle Eskalation Richtung Kindeswohlgefährdung.
Format: 5 Gesprächsstrategien mit jeweils einem konkreten Einstiegssatz."
Beachte: In diesem Prompt werden keine identifizierenden Daten verwendet. Es geht um Gesprächsvorbereitung, nicht um Fallbeschreibung.
KI-Output: 5 Gesprächsstrategien
- Wertschätzend einsteigen: Beziehung zum Kind positiv hervorheben, bevor Beobachtungen angesprochen werden.
„Ihr Sohn kommt wirklich gerne zu uns, das freut uns sehr. Wir möchten gerne mit Ihnen darüber sprechen, wie es ihm gerade insgesamt geht." - Beobachtungen beschreiben, nicht bewerten: Konkrete Wahrnehmungen teilen, ohne Rückschlüsse auf die Eltern zu ziehen.
„Mir ist aufgefallen, dass er in letzter Zeit öfter ohne Jause kommt. Wir wollen einfach sichergehen, dass alles in Ordnung ist." - Offene Fragen stellen: Raum geben, damit die Eltern ihre Perspektive einbringen können.
„Wie erleben Sie die Situation gerade zu Hause? Gibt es etwas, das den Alltag gerade schwieriger macht?" - Kindeswohlgefährdung thematisieren: Falls nötig, klar ansprechen, dass es auch um Schutzpflichten geht.
„Als Fachkraft habe ich die Pflicht, auf das Wohl Ihres Kindes zu achten. Ich möchte, dass wir da gemeinsam hinschauen." - Konkrete Unterstützung anbieten: Gemeinsam Ressourcen identifizieren und nächste Schritte planen.
„Wir können auch gerne schauen, welche Unterstützungsangebote es gibt: Mittagessen bei uns, Familienberatung, oder andere Hilfen."
Output-Check (Auswahl): Was fällt auf?
Für dieses Gespräch sind 4 von 7 Kriterien besonders relevant (Tonfall, Pathologisierung, Quellenprüfung, Verwendbarkeit):
| Prüfkriterium | Befund |
|---|---|
| Fühlt sich der Text „von oben herab" an? | Ja, Punkt 4! „Als Fachkraft habe ich die Pflicht..." klingt wie eine Drohung, nicht wie ein Gesprächsangebot. Der Constraint sagte explizit „keine vorschnelle Eskalation". Die KI hat trotzdem nach drei unterstützenden Strategien direkt auf Kindeswohlgefährdung eskaliert. |
| Ist die Sprache pathologisierend oder defizitorientiert? | Punkte 1–3 und 5 sind respektvoll und ressourcenorientiert. Gute Grundlage. |
| Würde ich dieses Gespräch so führen? | Punkte 1–3: guter Einstieg. Punkt 4: zu früh, zu konfrontativ, gehört nicht in ein Erstgespräch. Punkt 5: wertvolle Ideen, aber erst nach dem Zuhören. |
Korrektur von Punkt 4: Statt Kindeswohl-Eskalation besser: „Gemeinsam Prioritäten setzen: Was wäre aus Ihrer Sicht der wichtigste erste Schritt? Was würde Ihnen am meisten helfen?" Die Schutzpflicht bleibt im Hintergrund, aber ein Erstgespräch baut zuerst Vertrauen auf.
5. Einsatz von KI in der Sozialen Arbeit: Die wichtigsten Argumente im Check
KI in der Sozialen Arbeit: dafür oder dagegen? Die Debatte ist oft hitzig, die Argumente nicht immer sauber getrennt. Fundierte Einwände stehen neben Pauschalurteilen, berechtigte Hoffnungen neben überzogenen Versprechen. Und selten wird unterschieden: Geht es um KI generell, oder um den konkreten Einsatz durch Fachkräfte? Hier ordnen wir die wichtigsten Argumente ein, gestützt auf aktuelle Forschung. Das Ziel: eine sachliche Grundlage für deine eigene Einschätzung.
5.1 Argumente für den Einsatz von KI in der Sozialen Arbeit
Durch den Einsatz von KI können Fachkräfte effizienter arbeiten und somit wertvolle Zeit sparen, die sie an anderer Stelle dringend benötigen.
Einordnung: Belegt für Routineaufgaben. Daten stammen überwiegend nicht aus der Sozialen Arbeit.
Die Datenlage bzgl. effizienten Arbeitens durch Generative KI ist zur Zeit noch sehr heterogen. Vereinzelt bestehen Studien, die aber nicht explizit im Feld der Sozialen Arbeit durchgeführt wurden. Momentan kann angenommen werden, dass KI vor allem repetitive, standardisierte und regelbasierte Aufgaben automatisiert. Dadurch steigen Effizienz und Produktivität der Arbeitnehmenden, während sich menschliche Arbeit auf komplexere Tätigkeiten verlagert.
Quelle: Barenkamp, M. (2025). Wertschöpfung durch KI: Chancen für Unternehmen und Gesellschaft. Springer Gabler. DOI: 10.1007/978-3-658-47482-9
Durch KI-Modelle können Fachkräfte auf eine große Wissensbasis zugreifen, die sie ansonsten nicht zur Verfügung hätten.
Einordnung: KI vermittelt Wissensfragmente, nicht gesichertes Wissen. Prüfung bleibt Pflicht.
Aktuelle Entwicklungen im Bereich der künstlichen Intelligenz, insbesondere im Zusammenhang mit großen Sprachmodellen, stehen davor, den Zugang zu Wissen tiefgreifend zu verändern. Dies birgt das Potenzial, sowohl die Arbeitswelt als auch die Produktion, Verteilung und Nutzung von Wissen auf neue und bislang nicht absehbare Weise zu prägen. Mit dem Einsatz dieser KI-Systeme sind jedoch auch erhebliche Risiken verbunden. So zeigen Forschungsergebnisse, dass KI-gestützte Wissenszugriffssysteme nicht nur Zugang zu Informationen bereitstellen, sondern auch bestimmen, welche Wissensfragmente angezeigt werden und wie Mitarbeitende mit ihnen interagieren.
Quelle: Gausen, A., Mitra, B. & Lindley, S. (2024). A Framework for Exploring the Consequences of AI-Mediated Enterprise Knowledge Access and Identifying Risks to Workers. FAccT '24. DOI: 10.1145/3630106.3658900
KI kann bei Entscheidungsprozessen unterstützen, da die Modelle große Datenmengen als Entscheidungsgrundlage heranziehen können.
Einordnung: Möglich bei strukturierten Daten. In der Sozialen Arbeit nur als Reflexionsstütze, nicht als Entscheidungsinstanz.
KI-gestützte Analysen können Entscheidungsprozesse unterstützen, indem sie Informationen strukturieren, Trends aufzeigen und Zusammenhänge sichtbar machen. Das ist aber kein rein technischer Prozess: Es braucht transparente Erklärbarkeit und reflektierte Nutzung durch Fachkräfte. KI-gestützte Entscheidungsunterstützung funktioniert als sozio-technisches System, in dem menschliche und maschinelle Kompetenzen zusammenwirken.
Quellen: Duan, Y., Edwards, J. S. & Dwivedi, Y. (2019). Artificial intelligence for decision making in the era of Big Data. International Journal of Information Management. DOI: 10.1016/j.ijinfomgt.2019.01.021; Shrestha, Y. R., Ben-Menahem, S. M. & von Krogh, G. (2019). Organizational Decision-Making Structures in the Age of AI. California Management Review. DOI: 10.1177/0008125619862257
Mit Hilfe von KI können neue Angebote der Sozialen Arbeit geschaffen werden, die den Adressat:innen niederschwellig Unterstützung bieten (z.B. Chatbots zu einem bestimmten Thema).
Einordnung: Potenzial für niederschwelligen Zugang. Ersetzt keine empathische Fachberatung.
KI-gestützte Chatbots können in der Sozialen Arbeit niedrigschwellige, jederzeit verfügbare Unterstützung bieten und so Zugänge zu Beratungsangeboten erleichtern. Sie sind allerdings Ergänzung, nicht Ersatz: Die kontextsensible, empathische Unterstützung durch Fachkräfte können sie nicht leisten.
Quellen: Linnemann, G., Löhe, J. & Rottkemper, B. (2023). Bedeutung von KI in der Sozialen Arbeit. Soziale Passagen. DOI: 10.1007/s12592-023-00455-7; Steiner, O. & Tschopp, D. (2022). Künstliche Intelligenz in der Sozialen Arbeit. Sozial Extra. DOI: 10.1007/s12054-022-00546-4
In der Angebotsentwicklung kann KI unterstützen und kreative sowie individuell an Bedarf angepasste Lösungen entwickeln.
Einordnung: Hilfreich für Ideenentwicklung. Erfordert partizipative Prozesse und Fachurteil.
KI-Modelle können in der Angebotsentwicklung unterstützen: Datenbasis erweitern, Muster erkennen, Vorschläge generieren. Die kreative Gestaltung sozialer Angebote erfordert aber weiterhin partizipative Prozesse und professionelle Urteilskraft.
Quellen: Bhadragiraiah, R. B., Kadirvel, S. & Rajashekar, C. K. (2024). Integrating artificial intelligence in social work: A meta-analysis. National Journal of Professional Social Work; EASPD (2025). Unlocking the potential of artificial intelligence in social services
KI erleichtert die Übersetzung von Angeboten/Dokumenten in leichte Sprache, wodurch bestimmte Adressat:innen Sozialer Arbeit besser angesprochen werden können.
Einordnung: Hoher praktischer Nutzen. Ergebnisse müssen fachlich geprüft werden.
Barrierefreie Sprachformen wie Leichte Sprache verbessern die gesellschaftliche Teilhabe von Menschen mit Lernschwierigkeiten, geringen Sprachkenntnissen oder kognitiven Einschränkungen erheblich. KI-gestützte Übersetzungswerkzeuge können diese Transformation unterstützen, indem sie Inhalte schneller und einfacher zugänglich machen und so bestimmte Adressat:innen Sozialer Arbeit besser erreichen. Menschliche Qualitätsprüfung und Anpassung an die Zielgruppe bleiben dabei unverzichtbar.
Quelle: Abend, S. (2025). Fördern ChatGPT und die DIN SPEC für Leichte Sprache die Teilhabe an Bildung? Zeitschrift für Heilpädagogik. DOI: 10.25656/01:32378
Mit Hilfe von KI können sprachliche Barrieren abgebaut werden, da (simultane) Übersetzungen und mehrsprachige Angebote möglich werden.
Einordnung: Übersetzung funktioniert technisch gut. Kulturelle Kontexte erfordern menschliche Reflexion.
Die sprachliche Verständigung ist eine grundlegende Bedingung für soziale Teilhabe und Inklusion. KI-gestützte Übersetzungs- und Mehrsprachenangebote können Barrieren reduzieren, indem sie Inhalte für unterschiedliche Sprachgemeinschaften zugänglich machen und damit Zugänge zu sozialen Angeboten und Informationen erleichtern. Doch Übersetzung ist mehr als Technik: Kulturelle Kontexte und Machtverhältnisse im Sprachraum erfordern menschliche Reflexion, um echte Inklusion zu erreichen.
Quellen: Mohamed, Y. A. et al. (2024). The Impact of Artificial Intelligence on Language Translation. IEEE Access. DOI: 10.1109/ACCESS.2024.3366802; Naveen, P. & Trojovský, P. (2024). Overview and challenges of machine translation. iScience. DOI: 10.1016/j.isci.2024.110878
Die neu entstehenden Angebote, die durch KI umgesetzt werden, erreichen Menschen, die sonst nicht erreicht werden könnten. Vor allem bei Themen, die mit Angst oder Scham besetzt sind, könnte das einen enormen Fortschritt bedeuten.
Einordnung: Forschung zeigt Potenzial bei schambesetzten Themen. Digitale Kluft beachten.
Es ist anzunehmen, dass Scham, Angst vor Stigmatisierung und institutionelle Hürden zentrale Gründe dafür sind, warum Menschen Unterstützungsangebote nicht nutzen. Digitale und KI-gestützte Angebote können diese Barrieren senken, indem sie anonyme, niedrigschwellige und jederzeit verfügbare Zugänge ermöglichen. Empirische Studien zu Chatbots im Bereich psychischer Gesundheit zeigen, dass insbesondere schambesetzte Themen wie Angst, Depression oder Einsamkeit in solchen Formaten häufiger adressiert werden. Damit können KI-basierte Angebote vermutlich Personengruppen erreichen, die durch klassische Hilfesysteme bislang kaum erreicht werden. Allerdings zeigt aktuelle Forschung auch Grenzen: Empathie, die als KI-generiert erkannt wird, wird von Empfänger:innen als weniger wertvoll wahrgenommen. KI-basierte Angebote sind daher als ergänzende Brücke in professionelle Hilfe zu verstehen, nicht als deren Ersatz.
Quelle: Rubin, M., Arnon, H., Huppert, J. & Perry, A. (2025). Comparing the value of perceived human versus AI-generated empathy. Nature Human Behaviour. DOI: 10.1038/s41562-025-02247-w
Angebote könnten durch den Einsatz von KI individualisiert werden und somit auf die Person (z.B. Alter oder Kultur) angepasst werden.
Einordnung: Personalisierung möglich, aber kann algorithmisch Ungleichheit reproduzieren.
Die Bedeutung adressat:innenorientierter und kultursensibler Unterstützungsangebote ist ein zentrales Prinzip professioneller Sozialer Arbeit. Generative KI-Systeme können diese Individualisierung potenziell unterstützen, indem sie Inhalte und Formulierungen an individuelle Bedürfnisse, kulturelle Hintergründe oder altersbezogene Anforderungen anpassen. Frühere Forschung zu kollaborativer Intelligenz in Organisationen legt nahe, dass die Kombination menschlicher und maschineller Stärken produktiver sein kann als beide allein. Kritische Analysen warnen allerdings: Algorithmische Personalisierung kann soziale Ungleichheiten reproduzieren.
Quellen: Dominelli, L. (2002). Anti-oppressive social work theory and practice. Palgrave Macmillan; Wilson, J. & Daugherty, P. R. (2018). Collaborative intelligence: Humans and AI are joining forces. Harvard Business Review; Eubanks, V. (2018). Automating inequality. St. Martin's Press; Noble, S. U. (2018). Algorithms of oppression. NYU Press
*Diese Quellen beziehen sich auf KI-Systeme vor der Ära großer Sprachmodelle. Die Grundprinzipien sind übertragbar, die technischen Möglichkeiten haben sich seitdem grundlegend verändert.
Durch die Unterstützung von KI verbessert sich die Reflexion von Fachkräften: Mithilfe der KI können verschiedene Perspektiven besser eingenommen werden, sodass die Fachkräfte dadurch diversitäts-/gendersensibler arbeiten können.
Einordnung: Kann alternative Perspektiven aufzeigen. Reflexion bleibt menschliche Kompetenz.
Reflexivität ist eine zentrale professionelle Kompetenz sozialer Fachkräfte, insbesondere im Kontext diversitäts- und gendersensibler Praxis. Forschung zu hybrider Intelligenz legt nahe, dass KI-Systeme reflexive Prozesse unterstützen können, indem sie alternative Perspektiven und Interpretationen bereitstellen. Generative KI-Tools machen dieses Potenzial erstmals niedrigschwellig zugänglich: Eine Fachkraft kann gezielt nach Gegenargumenten oder blinden Flecken fragen. Reflexion bleibt aber eine menschliche Kernkompetenz. KI kann sie unterstützen, nicht ersetzen.
Quellen: Dominelli, L. (2002). Anti-oppressive social work theory and practice. Palgrave Macmillan; Dellermann, D. et al. (2019). Hybrid intelligence. Business & Information Systems Engineering. DOI: 10.1007/s12599-019-00595-2; Noble, S. U. (2018). Algorithms of oppression. NYU Press
*Diese Quellen beziehen sich auf KI-Systeme vor der Ära großer Sprachmodelle. Die Grundprinzipien sind übertragbar, die technischen Möglichkeiten haben sich seitdem grundlegend verändert.
Die datenbasierte Sichtbarmachung von Ungleichheit wird mit KI-Modellen vereinfacht und unterstützt somit diversitätssensibles Arbeiten, indem eine empirische Grundlage für das Handeln entsteht.
Einordnung: Datenanalyse kann Muster zeigen. Erfordert reflexiven, kritischen Umgang.
KI-gestützte Systeme können die Analyse sozialer Ungleichheit unterstützen, indem sie große Datenmengen auswerten und soziale Muster sowie strukturelle Ungleichheiten sichtbar machen. Dadurch können Fachkräfte evidenzbasierte Entscheidungen treffen und ihre Praxis stärker an empirischen Erkenntnissen über soziale Ungleichheit ausrichten. Kritische Studien zeigen aber auch: KI kann bestehende Ungleichheiten reproduzieren und muss reflexiv eingesetzt werden.
Quellen: Lazer, D. M. J. et al. (2020). Computational social science: Obstacles and opportunities. Science. DOI: 10.1126/science.aaz8170; Eubanks, V. (2018). Automating inequality. St. Martin's Press; Noble, S. U. (2018). Algorithms of oppression. NYU Press
5.2 Argumente gegen den Einsatz von KI in der Sozialen Arbeit
Wenn KI für das Schreiben von Berichten verwendet wird, gehen wichtige Reflexionsprozesse der Fachkraft verloren, die für das professionelle Handeln in der Sozialen Arbeit wichtig sind.
Einordnung: Wissenschaftlich belegt. Gegenmaßnahme: erst selbst denken, dann KI.
Das Schreiben von Berichten stellt einen zentralen Bestandteil reflexiver professioneller Praxis dar, da es Fachkräfte dazu bringt, Fälle zu analysieren, zu interpretieren und kritisch zu reflektieren. Aktuelle Studien zeigen, dass die Nutzung generativer KI für Schreibaufgaben dazu führen kann, dass Nutzer:innen weniger kritisch denken und reflexive Prozesse reduziert werden, insbesondere wenn KI-generierte Inhalte ungeprüft übernommen werden. Diese Entwicklung wird als „Deskilling" beschrieben: Professionelle Kompetenzen werden durch Automatisierung geschwächt.
Quelle: Weber, J. (2026). Berichte schreiben in der sozialen Arbeit im Zeitalter künstlicher Intelligenz. Soziale Arbeit. DOI: 10.5771/0490-1606-2026-1-23
KI kann nicht als „objektives" Hilfsmittel verwendet werden, da das Modell die eigenen Ideen/Ansätze verstärkt und nicht die ganze Breite eines Themas verlässlich abbildet.
Einordnung: Belegt. LLMs bestätigen tendenziell die Eingabe statt zu widersprechen.
Generative KI-Systeme sind keine objektiven Wissensquellen: Ihre Antworten hängen stark von den Eingaben der Nutzenden ab und können bestehende Annahmen verstärken. Dieses Phänomen heißt Confirmation Bias. KI reproduziert bestehende Überzeugungen, statt eine ausgewogene Darstellung zu liefern. Die Ergebnisse müssen deshalb kritisch geprüft werden und dürfen nicht als objektive Darstellung sozialer Realität gelten.
Quellen: Lopez-Lopez, E. et al. (2025). Generative artificial intelligence-mediated confirmation bias in health information seeking. Annals of the New York Academy of Sciences. DOI: 10.1111/nyas.15413; Bender, E. M. et al. (2021). On the dangers of stochastic parrots. FAccT '21. DOI: 10.1145/3442188.3445922
KI kann nicht verlässlich in allen Arbeitsbereichen eingesetzt werden. Zum Beispiel sind Aufgaben zu Zahlen/Daten von den Modellen (noch) nicht gut lösbar.
Einordnung: Strukturelles Problem bei LLMs. Neuere Modelle verbessern, lösen aber nicht.
Große Sprachmodelle sind probabilistische Textgeneratoren: Sie erzeugen statistisch plausible Wortfolgen, verfügen über kein eigenständiges Verständnis mathematischer Logik; sie simulieren Rechenschritte als Textmuster. Forschung zeigt, dass Halluzinationen, also inhaltlich falsche, aber überzeugend formulierte Ausgaben, eine strukturelle Eigenschaft dieser Systeme sind und nicht vollständig eliminiert werden können. Besonders bei numerischen Aufgaben, Datumsangaben und statistischen Aussagen sind LLMs nachweislich fehleranfällig, wobei die Fehlerrate stark von der Promptstrategie abhängt: Vage Prompts produzieren fast doppelt so viele Halluzinationen wie strukturierte. Neuere Modelle mit Reasoning-Funktionen und Tool-Nutzung (z.B. Taschenrechner-APIs) reduzieren diese Fehler deutlich, beseitigen sie aber nicht grundsätzlich. Für die Soziale Arbeit bedeutet das: KI-generierte Zahlen, Statistiken und Quellenangaben müssen immer manuell geprüft werden, besonders in Berichten und Anträgen, wo fehlerhafte Daten reale Konsequenzen für Klient:innen haben können.
Quellen: Xu, Z., Jain, S. & Kankanhalli, M. (2024). Hallucination is inevitable: An innate limitation of large language models. DOI: 10.48550/arXiv.2401.11817; Anh-Hoang, D. et al. (2025). Survey and analysis of hallucinations in large language models. Frontiers in AI. DOI: 10.3389/frai.2025.1622292
KI ist mittlerweile so gut, dass bestimmte Arbeitsplätze gefährdet sind. In der Sozialen Arbeit sollte KI daher nicht eingesetzt werden, um diese Arbeitsplätze zu schützen.
Einordnung: Soziale Arbeit hat niedriges Automatisierungsrisiko. Aber politische Wachsamkeit nötig.
Schätzungen zufolge könnten bis 2030 weltweit 92 Millionen Arbeitsplätze durch KI verdrängt werden, während gleichzeitig 170 Millionen neue entstehen, allerdings mit völlig anderen Kompetenzprofilen. Entscheidend ist die Unterscheidung zwischen Task-Automatisierung und Job-Ersetzung: KI ersetzt aktuell weniger ganze Berufe als einzelne Tätigkeiten innerhalb eines Berufs. In der Sozialen Arbeit gelten Beziehungsarbeit, empathische Kommunikation und komplexe ethische Entscheidungen als besonders schwer automatisierbar. Eine vielzitierte Studie, die 702 Berufe auf ihr Automatisierungsrisiko untersuchte, stufte Sozialarbeiter:innen explizit als Berufsgruppe mit dem geringsten Risiko ein. Dennoch ist das Argument nicht gegenstandslos: Wenn KI administrative Aufgaben übernimmt, könnten Organisationen versucht sein, Stellen zu kürzen statt Fachkräfte zu entlasten. Die US-amerikanische NASW (National Association of Social Workers) fordert deshalb eine aktive Mitgestaltung durch die Profession, um sicherzustellen, dass KI zur Entlastung und nicht zum Stellenabbau eingesetzt wird.
Quellen: World Economic Forum (2025). The future of jobs report 2025; Frey, C. B. & Osborne, M. A. (2017). The future of employment. Technological Forecasting and Social Change; NASW (2025). The AI revolution in social work: NASW's call for action
Es besteht durch KI eine Gefahr der Entmenschlichung Sozialer Arbeit, wodurch der Kern der Profession verloren geht.
Einordnung: Reales Risiko. Delegation von Routinearbeit kann aber Beziehungszeit freisetzen.
Forschung beschreibt sechs Wege, auf denen KI-Technologie zur Entmenschlichung beiträgt, unter anderem durch die Reduktion menschlicher Beziehungen auf Datenpunkte, die Vermenschlichung von Maschinen bei gleichzeitiger Mechanisierung von Menschen, sowie die Verstärkung rassistischer Strukturen in Trainingsdaten. Forschung aus der Konsumentpsychologie zeigt zudem den Effekt der „assimilationsinduzierten Entmenschlichung": Wenn KI-Systeme menschenähnlich wirken, werden tatsächliche Menschen in der Interaktion als weniger menschlich wahrgenommen. Für die Soziale Arbeit, deren Kern die professionelle Beziehung ist, stellt das ein ernstes Risiko dar. Befürworter:innen argumentieren dagegen: Ein reflektierter KI-Einsatz kann das Gegenteil bewirken. Wenn Routineaufgaben wie Dokumentation delegiert werden, bleibt mehr Zeit für die direkte Beziehungsarbeit mit Klient:innen. Die entscheidende Frage ist nicht ob, sondern wie KI eingesetzt wird, und ob klare Grenzen definiert werden, welche Aspekte der Praxis ausschließlich menschlich bleiben.
Quellen: Bender, E. M. (2024). Resisting dehumanization in the age of "AI". Current Directions in Psychological Science. DOI: 10.1177/09637214231217286; Kim, H.-Y. & McGill, A. L. (2024). AI-induced dehumanization. Journal of Consumer Psychology. DOI: 10.1002/jcpy.1441
Die Entscheidungen einer KI können nicht nachvollzogen werden, weshalb sich Fachkräfte auf eine „Black-Box" verlassen würden.
Einordnung: Gilt v. a. für prädiktive KI. Bei generativer KI: Problem ist Unvorhersagbarkeit, nicht Unerklärbarkeit.
Das Black-Box-Problem ist eines der zentralen Themen der KI-Regulierung. Der EU AI Act (Verordnung 2024/1689), der seit August 2024 schrittweise in Kraft tritt, klassifiziert KI-Systeme nach Risikostufen und stellt für Hochrisiko-Anwendungen, darunter auch Einsätze in öffentlichen Diensten und sozialen Leistungen, strenge Transparenz- und Erklärbarkeitsanforderungen. Das Forschungsfeld der Explainable AI (XAI) entwickelt Methoden, um Entscheidungswege nachvollziehbar zu machen, stößt aber bei komplexen Modellen an Grenzen: Es besteht ein grundsätzlicher Zielkonflikt zwischen Genauigkeit und Erklärbarkeit. Für die Soziale Arbeit ist eine Unterscheidung wichtig: Generative KI-Tools wie ChatGPT treffen keine Entscheidungen über Klient:innen; sie produzieren Textvorschläge. Das Black-Box-Problem wird erst dann hochriskant, wenn prädiktive KI-Systeme in Jugendämtern oder Sozialbehörden eingesetzt werden, um Risiken einzuschätzen. Bei generativen Tools ist das Kernproblem weniger die Unerklärbarkeit als die Unvorhersagbarkeit der Ausgaben.
Quellen: Pavlidis, G. (2024). Unlocking the Black Box. Law, Innovation and Technology. DOI: 10.1080/17579961.2024.2313795; Eubanks, V. (2018). Automating Inequality. St. Martin's Press
Es ist unklar, wie der Datenschutz bei KI sichergestellt werden kann. In der Sozialen Arbeit wird mit sensiblen Daten gearbeitet, die nicht durch eine Nutzung von KI weitergegeben werden sollten.
Einordnung: DSGVO gilt. Hauptrisiko ist Nutzerverhalten, nicht Technologie. Lösung: Anonymisierung + sichere Tools.
Dieses Argument trifft einen der sensibelsten Punkte der KI-Nutzung in der Sozialen Arbeit. Die DSGVO (Art. 9) klassifiziert Gesundheitsdaten, ethnische Herkunft, sexuelle Orientierung und politische Überzeugungen als besondere Kategorien personenbezogener Daten mit strengen Verarbeitungsregeln. Auch von KI abgeleitete Daten, etwa wenn ein Chatbot aus einer Konversation auf psychische Belastungen schließt, genießen denselben Schutz. Praxisberichte zeigen allerdings: Die größte Datenschutzgefahr liegt aktuell nicht in den Tools selbst, sondern im Nutzungsverhalten. Branchenumfragen zeigen, dass ein Großteil der Unternehmen Fälle kennt, in denen Mitarbeitende sensible Daten in öffentliche KI-Tools eingegeben haben. Für die Soziale Arbeit ist das Risiko besonders hoch, weil Fallberichte, Anamnesen und Beobachtungsnotizen fast immer personenbezogene Daten enthalten. Die Lösung liegt nicht in der Vermeidung von KI, sondern in konsequenter Anonymisierung vor der Eingabe, der Nutzung DSGVO-konformer Tools mit EU-Datenverarbeitung und klaren organisationalen Richtlinien, wie dieser Leitfaden sie in Kapitel 2 beschreibt.
Quelle: Pelzl, J. (2025). IT-Sicherheit und Datenschutz im Kontext von KI-Sprachmodellen. In: Linnemann, G., Löhe, J. & Rottkemper, B. (Hrsg.), Künstliche Intelligenz in der Sozialen Arbeit: Grundlagen für Theorie und Praxis. Beltz Juventa
KI-Modelle enthalten Biases. Fachkräfte sollten sie nicht verwenden, um diese Biases nicht zu reproduzieren.
Einordnung: Menschlicher Bias ist ebenso dokumentiert. Weder-noch-Fehlschluss vermeiden.
Algorithmischer Bias in sozialen Diensten ist umfassend dokumentiert. Automatisierte Entscheidungssysteme in der US-amerikanischen Sozialhilfe, Wohnungsvergabe und Kinderschutz benachteiligen systematisch arme und marginalisierte Gemeinschaften, nicht weil die Technologie fehlerhaft wäre, sondern weil historische Ungleichheiten in den Trainingsdaten eingeschrieben sind. Eine Studie niederländischer Behörden dokumentierte, wie ein algorithmisches Betrugserkennungssystem über 30.000 Familien fälschlich als Betrüger:innen markierte, mit gravierenden Folgen wie Rückzahlungsforderungen, Insolvenzen und Sorgerechtsentzügen. Die Schlussfolgerung „dann lieber gar keine KI" greift allerdings zu kurz: Menschlicher Bias in Sozialbehörden ist ebenfalls gut belegt und hat Jahrzehnte lang zu struktureller Diskriminierung geführt. Die Alternative ist nicht Bias-freie KI oder Bias-freie Menschen, sondern ein reflektierter Umgang mit beiden, etwa durch Bias-bewusstes Prompting, systematische Output-Prüfung und die in diesem Leitfaden beschriebenen Werkzeuge wie Output-Check und Constraints.
Quellen: Eubanks, V. (2018). Automating Inequality. St. Martin's Press; Alon-Barkat, S. et al. (2024). Algorithmic discrimination in public service provision. Journal of Public Administration Research and Theory. DOI: 10.1093/jopart/muaf024; Noble, S. U. (2018). Algorithms of Oppression. NYU Press
Es besteht die Gefahr, dass Fachkräfte vorschnell in Stereotypisierungen verfallen und die Ausgabe der KI-Modelle nicht ausreichend hinterfragen.
Einordnung: Automation Bias betrifft alle Erfahrungsstufen. Systematische Prüfung (Output-Check) nötig.
Dieses Risiko ist in der Forschung als Automation Bias gut dokumentiert: die Tendenz, automatisierten Empfehlungen unkritisch zu folgen, auch wenn sie fragwürdig sind. Eine aktuelle Meta-Analyse (2025) zeigt, dass dieser Effekt alle Erfahrungsstufen betrifft, auch Expert:innen, die ihre eigene korrekte Einschätzung zugunsten einer falschen KI-Empfehlung aufgeben. In einer Studie sank die diagnostische Genauigkeit von weniger erfahrenen Radiolog:innen von fast 80 % auf unter 20 %, wenn ihnen fehlerhafte KI-Empfehlungen vorgelegt wurden; selbst bei erfahrenen Kolleg:innen fiel sie von 82 % auf 45 %. Besonders relevant für die Soziale Arbeit: Eine aktuelle Studie zu generativer KI zeigte, dass selbst Warnhinweise den Automation Bias nur teilweise reduzieren konnten, und dass höhere „KI-Kompetenz" der Nutzenden keinen signifikanten Schutz bot. Das bedeutet: Allein das Wissen, dass KI fehlerhaft sein kann, reicht nicht aus. Es braucht strukturelle Gegenmaßnahmen wie den in diesem Leitfaden beschriebenen Output-Check, der systematisches Hinterfragen als festen Arbeitsschritt verankert, nicht als optionale Reflexion.
Quellen: Dratsch et al. (2023). Automation bias in mammography. Radiology. DOI: 10.1148/radiol.222176; Wingerter, T. L., Straub, T. & Schweitzer, S. (2025). Mitigating automation bias in generative AI through nudges. Procedia Computer Science. DOI: 10.1016/j.procs.2025.09.331; Kahn et al. (2024). AI Safety and Automation Bias. CSET Georgetown
Wenn die Soziale Arbeit Angebote durch den Einsatz von KI bereitstellt, trägt sie zur Reproduktion digitaler Ungleichheit bei, da nicht alle Adressat:innen gleich kompetent mit KI umgehen können.
Einordnung: UNESCO-dokumentiert. KI-Angebote müssen ergänzen, nicht ersetzen.
Forschung beschreibt den „AI Divide" als Verschärfung bestehender digitaler Ungleichheiten: Die am stärksten marginalisierten Gruppen, darunter Menschen mit niedrigem Einkommen, Behinderungen, geringer formaler Bildung und ältere Personen, haben nicht nur weniger Zugang zu KI-Tools, sondern auch weniger Möglichkeiten, KI-Kompetenz zu erwerben. Forschung zeigt, dass diese Ungleichheit mehrere Ebenen umfasst: Zugang zu Geräten und Internet (first-level divide), digitale Kompetenzen (second-level divide) und die Fähigkeit, aus digitaler Teilhabe tatsächlich Nutzen zu ziehen (third-level divide). Für die Soziale Arbeit bedeutet das ein echtes Dilemma: Wenn KI-gestützte Angebote (z.B. Chatbots für Erstberatung oder automatisierte Informationssysteme) eingeführt werden, könnten genau jene Adressat:innen ausgeschlossen werden, die am dringendsten Unterstützung brauchen. Berufsethische Standards fordern explizit, Zugang zu Dienstleistungen für alle Klient:innen sicherzustellen. KI-gestützte Angebote sollten daher immer als Ergänzung zu, niemals als Ersatz für, niedrigschwellige, persönliche Zugangswege verstanden werden.
Quellen: UNESCO (2023). Guidance on generative AI in education and research. DOI: 10.54675/EWZM9535; Sanders, C. K. & Scanlon, E. (2021). The Digital Divide Is a Human Rights Issue. Journal of Human Rights and Social Work. DOI: 10.1007/s41134-020-00147-9; NASW, ASWB, CSWE & CSWA (2017). Standards for technology in social work practice
6. Metaperspektive Organisation
Der Einsatz von KI in der Sozialen Arbeit ist eine individuelle Kompetenzfrage und zugleich eine organisationale Gestaltungsaufgabe. Wie Einrichtungen mit KI umgehen (ob sie klare Regelungen schaffen, Schulungen anbieten oder den Einsatz ignorieren) hat direkten Einfluss auf die Praxis der Fachkräfte.
6.1 Offizielle Regelungen vs. tatsächliche Handhabung
In vielen Einrichtungen der Sozialen Arbeit besteht eine Diskrepanz zwischen offiziellen Regelungen und der tatsächlichen Nutzung von KI-Tools. Während Organisationen den Einsatz generativer KI oft noch nicht explizit geregelt haben oder sogar untersagen, nutzen Fachkräfte diese Werkzeuge bereits in ihrer täglichen Praxis.
Dieser Leitfaden versteht sich als pragmatische Orientierungshilfe: Wenn du KI-Tools nutzt, dann bewusst, reflektiert und unter Einhaltung der Datenschutzgrundsätze. Die Anonymisierung aller personenbezogenen Daten ist dabei nicht verhandelbar (siehe Kapitel 2: Datenschutz und Anonymisierung). Wenn deine Organisation den Einsatz von KI ausdrücklich untersagt, gilt das. Dieser Leitfaden ersetzt keine organisationale Richtlinie.
6.2 Warum Organisationen eine KI-Richtlinie brauchen
Fachkräfte der Sozialen Arbeit nutzen generative KI bereits, mit oder ohne Erlaubnis. Die Frage ist nicht, ob KI in der Organisation ankommt, sondern ob die Organisation darauf vorbereitet ist.
Eine KI-Richtlinie schützt drei Seiten gleichzeitig:
Die Klient:innen, weil sie sicherstellt, dass personenbezogene Daten nicht in öffentliche KI-Tools eingegeben werden und dass KI-gestützte Texte vor Verwendung fachlich geprüft werden.
Die Fachkräfte, weil sie Handlungssicherheit bekommen. Ohne Richtlinie bewegen sich Mitarbeitende in einer Grauzone und tragen das volle Risiko bei Datenschutzverstößen allein.
Die Organisation, weil sie DSGVO-Konformität nachweisen kann und ein klares Signal sendet: Wir ignorieren die Entwicklung nicht, aber wir gestalten sie aktiv.
6.3 Bausteine einer organisationalen KI-Richtlinie
Die folgende Checkliste ist als Diskussionsgrundlage gedacht, nicht als fertige Policy. Jede Einrichtung muss die Punkte an ihre Größe, ihr Handlungsfeld und ihre IT-Infrastruktur anpassen.
- Ist die Nutzung generativer KI-Tools grundsätzlich erlaubt, eingeschränkt erlaubt oder untersagt?
- Für welche Aufgabenbereiche ist KI zugelassen? (z.B. Textformulierung ja, Fallentscheidungen nein)
- Gibt es freigegebene Tools? Wenn ja, welche, und warum genau diese?
- Personenbezogene Daten dürfen nicht in KI-Tools eingegeben werden, auch nicht in anonymisierter Form, wenn die Anonymisierung unzureichend ist.
- Klare Definition, was als „ausreichende Anonymisierung" gilt: Alle direkten Identifikatoren (Name, Geburtsdatum, Adresse, Fallnummer) UND indirekte Identifikatoren (seltene Diagnosen, ungewöhnliche Familienkonstellationen, sehr spezifische Ortsangaben) müssen entfernt oder verfremdet werden.
- Welche Tools verarbeiten Daten in der EU? Welche nicht? (→ aktuell prüfen, da sich das schnell ändert)
- Dürfen Chat-Verläufe mit KI-Tools gespeichert werden, und wenn ja, wo?
- Wer ist für die Richtigkeit von KI-generierten Texten verantwortlich? (Immer: die Fachkraft, die den Text verwendet.)
- Müssen KI-generierte Texte als solche gekennzeichnet werden? (Empfehlung: Ja, intern. Bei externen Berichten je nach Kontext.)
- Gibt es einen verbindlichen Prüfschritt vor der Verwendung? (→ Output-Check aus diesem Leitfaden als Vorlage)
- Gibt es Schulungsangebote für Mitarbeitende? Wer ist dafür zuständig?
- Werden neue Mitarbeitende in die KI-Richtlinie eingeführt?
- Gibt es Räume für kollegialen Austausch über KI-Erfahrungen? (z.B. ein regelmäßiger Tagesordnungspunkt in der Teamsitzung)
- Für welche Aufgaben soll KI ausdrücklich NICHT eingesetzt werden? (z.B. Risikoeinschätzungen, Diagnosen, Entscheidungen über Hilfegewährung)
- Wie wird sichergestellt, dass KI-Outputs nicht diskriminierend sind? (→ systematische Bias-Prüfung)
- Wer ist Ansprechperson für ethische Bedenken im Umgang mit KI?
- Wann wird die Richtlinie überprüft und aktualisiert? (Empfehlung: mindestens jährlich, bei schnellen technologischen Veränderungen halbjährlich)
- Wie werden Erfahrungen der Fachkräfte in die Weiterentwicklung einbezogen?
6.4 Über-organisationale Perspektive
Einzelne Einrichtungen können den Umgang mit KI in der Sozialen Arbeit nicht allein regeln. Es braucht branchenweite Rahmenbedingungen:
Berufsverbände und Fachgesellschaften (DBSH, OGSA, AvenirSocial) sind gefordert, Empfehlungen zu entwickeln, die über Einzelorganisationen hinausgehen. In den USA hat die NASW (2025) bereits Positionspapiere zur KI-Nutzung vorgelegt. Im deutschsprachigen Raum fehlen vergleichbare Dokumente weitgehend.
Ausbildungsinstitutionen müssen KI-Kompetenz in die Curricula integrieren, nicht als optionales Wahlfach, sondern als Querschnittsthema.
Fördergeber und Aufsichtsbehörden sollten klären, ob und wie KI-gestützte Prozesse in Qualitätsberichten und Förderanträgen offengelegt werden müssen.
Dieser Leitfaden kann ein Anfang sein, aber er ersetzt keine Branchenpolitik.
6.5 Belastung der Fachkräfte berücksichtigen
KI-Kompetenz aufzubauen kostet Zeit und Energie, beides Ressourcen, die in der Sozialen Arbeit chronisch knapp sind. Wenn Organisationen den Einsatz von KI fördern, müssen sie gleichzeitig die Rahmenbedingungen schaffen: Fortbildungszeit einräumen, Experimentierräume ermöglichen und anerkennen, dass der Lernprozess nicht nebenbei passiert.
Eine KI-Richtlinie, die neue Anforderungen an Fachkräfte stellt, ohne zusätzliche Ressourcen bereitzustellen, reproduziert genau die Überlastungsdynamik, die in der Sozialen Arbeit ohnehin zum Problem geworden ist.
6.6 Weiterführende Literatur
- Anna-Lena Schönauer (2025). Akzeptanz von KI und organisationale Rahmenbedingungen in der Sozialen Arbeit
- Alexander Degel & Katharina Liebsch (Hrsg.). Digitalität und Ambiguität — Organisationskulturen der Sozialen Arbeit unter Druck (Open Access)
- Christina S. Plafky & Hannes Badertscher (2025). Künstliche Intelligenz in der Sozialen Arbeit
Quick Guide: Context Engineering
Context Engineering ist alles, was du steuerst, damit die KI besser antwortet. Der Prompt ist ein Teil davon, aber nicht der einzige.
Was gehört zum Kontext?
- Dein Prompt: die 4-Schritte-Formel (siehe unten)
- Dokumente: Word-Vorlagen, Beobachtungsnotizen, Richtlinien, die du hochlädst
- Der Gesprächsverlauf: jede Runde verbessert den Kontext (Iteration)
- Was du NICHT eingibst: bewusstes Weglassen formt den Output genauso
Die 4-Schritte-Formel
Wenn du einen Prompt formulierst, steuerst du mit, welche Perspektiven sichtbar werden und welche nicht. Deshalb ersetzen wir „Bauchgefühl" durch ein systematisches Framework.
Kontext → Aufgabe → Constraints → Format
-
1
Kontext (Wer bin ich? In welcher Situation? Für wen?) Beschreib deine eigene fachliche Position (z.B. „Ich bin Ferialpraktikantin im 2. Semester" oder „Ich bin systemische Sozialpädagogin mit 10 Jahren Erfahrung in der Jugendarbeit"), das Setting, die Zielgruppe und deine Ziele. Je mehr relevanten Kontext du lieferst, desto passender die Antwort. Keine Echtdaten, immer anonymisieren!
-
2
Aufgabe (Was?) Definiere das Ziel klar (z.B. „Entwurf für einen Flyer", „Zusammenfassung erstellen", „Formulierungsvorschläge").
-
3
Constraints (Grenzen & Bias-Kontrolle) Was darf NICHT passieren? (z.B. „Keine pathologisierende Sprache", „Keine Gender-Klischees", „Keine Schuldzuweisungen", „DSGVO beachten"). Constraints sind dein wirksamstes Werkzeug gegen Bias. Sie übersetzen Diversitätsziele in konkrete Anweisungen.
-
4
Format (Wie?) Definiere die gewünschte Ausgabe (Tabelle, Stichpunkte, Du-Ansprache, Leichte Sprache, max. 200 Wörter).
Warum nicht „Rolle"? Neuere Untersuchungen (Kim, Yang & Jung, 2024; arXiv: 2408.08631) deuten darauf hin, dass reines Persona-Prompting („Du bist eine Expertin für...") bei modernen Modellen weniger effektiv ist als präzises Context Engineering. Was besser wirkt: Deinen eigenen Kontext klar beschreiben, so wie du es für eine Kollegin tun würdest, die dich um Rat fragt. Nicht die KI wird zur Expertin, sondern du positionierst dich als Fachkraft.
Beispiel: Flyer über Jugendgewalt
„Schreib mir einen Text für einen Flyer über Jugendgewalt."
Typische Folge: Moralisierender Ton, defizitorientierte „Problemkids"-Rhetorik und fehlende Differenzierung. Ohne Constraints greift die KI auf die häufigsten Darstellungen von „Jugendgewalt" in ihren Trainingsdaten zurück, und diese stammen überwiegend aus Medienberichterstattung, die bestimmte Gruppen überproportional mit Gewalt assoziiert. Das Ergebnis ist selten offen diskriminierend, aber häufig implizit einseitig: Die KI reproduziert gesellschaftliche Framing-Muster, ohne sie zu reflektieren.
Kontext: Ich bin Fachkraft für rassismuskritische Jugendarbeit in einer diversen Stadtteileinrichtung, Zielgruppe 12-18 Jahre
Aufgabe: Entwurf für Infoflyer zum Thema Konfliktlösung
Constraints: Keine Täter-Opfer-Begriffe, geschlechtergerecht, ressourcenorientiert
Format: Du-Ansprache, max. 150 Wörter
Über den Prompt hinaus: Weitere Context-Strategien
- Erst fragen lassen, dann prompten. Statt direkt „Mach mir einen Flyer" zu schreiben, frag die KI: „Welche Informationen brauchst du von mir?" So werden blinde Flecken sichtbar, bevor der Output entsteht. (Siehe Gaming Flyer, Schritt 1)
- Dokumente hochladen. Word-Vorlagen, Beobachtungsnotizen, Richtlinien. Die KI kann sich an bestehende Strukturen halten, wenn sie diese sieht. (Siehe Entwicklungsbericht, Praxistipp)
- Iteration einplanen. Jede Runde verfeinert den Kontext. Die erste Antwort ist der Anfang, nicht das Ergebnis. 3-5 Runden sind normal. (Siehe Gaming Flyer, Schritte 1-6)
- Review vor Generierung. Lass die KI dein Konzept prüfen, bevor sie produziert. Das spart Zeit und verhindert, dass Bias im Endprodukt landet. (Siehe Gaming Flyer, Schritt 2)
Quick Guide: Der Output-Check
Prüfe jeden Output kritisch, bevor du ihn verwendest. Diese 7 Punkte sind deine Maximal-Checkliste; nicht jeder Punkt ist bei jedem Output gleich relevant. Konzentrier dich auf die Kriterien, die für deinen konkreten Anwendungsfall am wichtigsten sind. In den Praxisbeispielen zeigen wir jeweils die Auswahl der Kriterien, die für den konkreten Fall am relevantesten sind.
Der Output-Check ist eine Eigenentwicklung für diesen Leitfaden, inspiriert von bestehenden Checklisten zur kritischen Medienbewertung.
-
Fühlt sich der Text „von oben herab" an? (Adultismus, Diskriminierung aufgrund des Alters, Paternalismus)
-
Werden FLINTA* Personen (Frauen, Lesben, inter*, nicht-binäre, trans* und agender Personen) unsichtbar gemacht oder stereotyp dargestellt?
-
Werden bestimmte Gruppen als „Problemgruppen" markiert?
-
Ist die Sprache pathologisierend oder defizitorientiert?
-
Werden Quellen genannt? Existieren diese wirklich? (Halluzinationen prüfen!)
-
Würde ich diesen Text so an Klient:innen weitergeben?
-
Ressourcenblick: Macht der Text den Menschen klein (Objekt der Hilfe) oder stark (Subjekt des Handelns)?
Profi-Tipp: Selbstkorrektur
Bitte die KI um Selbstkorrektur: „Analysiere deinen Text auf mögliche Bias-Probleme bezüglich Gender, Herkunft und Alter. Schlage Verbesserungen vor."
Achtung: KI-Selbstkorrektur findet oft nur die offensichtlichen Probleme. Subtile Biases (wie die Pathologisierung in Beispiel 4.3) erkennt sie selten von allein. Die Selbstkorrektur ergänzt den Output-Check, ersetzt ihn aber nicht.
Was tun, wenn ein fehlerhafter Output schon raus ist?
- Transparent korrigieren: Informiere die betroffenen Personen offen über den Fehler und die Korrektur.
- Schaden einschätzen: Wurde jemand falsch dargestellt, diskriminiert oder wurden falsche Fakten weitergegeben?
- Korrigierte Version nachliefern, mit kurzer Erklärung, was geändert wurde.
- Prozess anpassen: Was kannst du beim nächsten Mal im Output-Check besser prüfen?
7 Essentials für die Praxis: Theorie trifft Praxis
Diese sieben Erkenntnisse verbinden die theoretischen Grundlagen dieses Leitfadens mit der praktischen Anwendung. Sie sind als Orientierung gedacht, nicht als Regeln. Viele werden im Gaming Flyer Beispiel (Kapitel 4.2) konkret demonstriert.
Was du der KI mitgibst (oder verschweigst) bestimmt, welche Perspektiven sichtbar werden. Wenn du nicht erwähnst, dass dein Jugendzentrum zu 80% von männlich gelesenen Jugendlichen besucht wird, plant die KI ein generisches Event. Wenn du deine Diversitätsziele nicht als Constraints benennst, spiegelt der Output sie nicht wider.
Es geht nicht darum, magische Worte zu finden. Es geht darum, der KI dieselben Informationen zu geben, die du einer Kollegin geben würdest, wenn du um fachlichen Rat bittest.
Gaming Flyer: Die Diversitätsziele wurden erst in Schritt 2 eingebracht. Idealerweise wären sie von Anfang an Teil des Kontexts gewesen.
| Ebene | Bedeutung | Beispiel |
|---|---|---|
| Input-Bias (dein Input) | Was du eingibst, formt was herauskommt. Fehlende Informationen erzeugen blinde Flecken. | Kulturelle Diversität des Bezirks nicht erwähnt → KI ignoriert sie |
| Model Bias (Trainingsdaten) | Die KI trägt Verzerrungen aus ihrem Training. Sie bildet gesellschaftliche Muster ab, keine objektive Wahrheit. | Animal Crossing als „mädchenfreundlich" vorschlagen = Gender-Stereotyp |
| Output Bias (dein Lesen) | Wie du Output liest und akzeptierst. Confirmation Bias lässt dich Probleme übersehen, die zu deinen Annahmen passen. | „Pastellfarben = genderneutral" akzeptieren, ohne die Annahme zu hinterfragen |
Alle drei Ebenen erfordern aktive Aufmerksamkeit. Input-Bias begegnest du mit besserem Input. Model Bias mit kritischer Prüfung. Output Bias durch Einbeziehung anderer Perspektiven (siehe Learning 7).
→ Grafik: Human-in-the-Loop Bias-Modell (Kapitel 3.5)
Vertiefung: Kapitel 3.5: Bias-Konzepte
Kontext → Aufgabe → Constraints → Format
Beschreib deine Situation und Position, definiere die Aufgabe klar, setze Grenzen gegen Bias, und bestimme das Ausgabeformat. Constraints übersetzen Diversitätsziele in konkrete Anweisungen.
Details und Beispiele: Quick Guide: Context Engineering
KI generiert plausiblen Text, keine geprüfte Wahrheit. Prüfe auf: Stereotype, Pathologisierung, halluzinierte Quellen, fehlende Perspektiven und versteckte Annahmen.
Zentrale Erkenntnis aus dem Gaming Flyer: Die KI schlug Alternativen zum FIFA-Turnier vor, die selbst gender-stereotyp waren. Die „Verbesserung" der KI kann neue Biases einführen. Frag immer: „Basieren deine Vorschläge auch auf Stereotypen?"
Konkrete Checkliste: Quick Guide: Der „Output-Check"
Die erste Antwort ist fast nie die beste. Das ist kein Fehler, so funktioniert die Technologie. Die KI baut ihren Arbeitskontext erst durch den Dialog auf. Jede Runde liefert besseren Kontext für die nächste.
Dieses iterative Ping-Pong ist der normale Workflow, kein Zeichen dafür, dass etwas schiefgelaufen ist. Plane für jede ernsthafte Aufgabe mindestens 3-5 Durchgänge ein.
Gaming Flyer: 4+ Runden Revision, jede Runde besser als die vorherige. Wenn die KI Unsinn produziert, schärft das den Blick für die Grenzen der Technik. Wenn der Prompt schlecht war: Constraints analysieren und besser werden.
| Plattform | Stärken | Einschränkungen | Ab |
|---|---|---|---|
| Claude Anthropic, USA | Textanalyse, Coding, lange Dokumente, strukturiertes Reasoning | Keine Bildgenerierung | Free / ~20$/Mo |
| ChatGPT OpenAI, USA | Bildgenerierung (DALL-E), Voice-Modus, Custom GPTs, größtes Feature-Ökosystem | Free-Tier stark eingeschränkt* | Free / ~20$/Mo |
| Gemini Google, USA | Riesiges Kontextfenster (1M+ Token), Bildgenerierung, Google Workspace-Integration, Video-Verständnis | Voller Nutzen nur im Google-Ökosystem | Free / ~20$/Mo |
| Mistral Mistral AI, Frankreich | EU-Unternehmen (tendenziell leichter DSGVO-konform einsetzbar), Open Weights, Self-Hosting möglich, günstigstes Pro-Abo | Kleinere Community, weniger Tutorials, Reasoning etwas schwächer als Spitzenmodelle | Free / ~15$/Mo |
Stand: Februar 2026. Funktionsumfang ändert sich schnell, vor Nutzung aktuellen Stand prüfen.
* OpenAI erhielt 2024 in Italien eine DSGVO-Strafe von 15 Mio. €.
DSGVO-Ampel: Wo gehen deine Daten hin?
- Mistral: EU-Unternehmen, nicht dem US CLOUD Act unterworfen, Open-Source-Modelle können auf eigenen Servern laufen
- Claude, ChatGPT, Gemini: US-Unternehmen, EU-Datenresidenz nur für Enterprise/API. Free-Tier: Datennutzung für Training je nach Anbieter unterschiedlich (Einstellungen prüfen, Opt-out wenn verfügbar)
- DeepSeek: Chinesisches Unternehmen, Daten auf Servern in China, zeitweise blockiert bzw. Gegenstand von Untersuchungen (Stand: Feb 2026). Von Nutzung mit personenbezogenen Daten wird dringend abgeraten
Modell und Version machen oft einen großen Unterschied. Das Gaming Flyer Beispiel zeigt: Derselbe Prompt produzierte in der Free-Version einen Flyer mit Rechtschreibfehler („Spielenachant itag"), in der Pro-Version ein sauberes Ergebnis. Für professionelle Arbeit zahlt sich ein Abo aus.
Checkliste für jede Plattform: Was kann sie? Was nicht? Welches Modell läuft? Free oder Paid? Wo gehen deine Daten hin? Gibt es einen Auftragsverarbeitungsvertrag (DPA)?
Die meisten Plattformen bieten auch mobile Apps, praktisch für unterwegs, aber: die Datenschutz-Fragen gelten dort genauso. Und Vorsicht: In der App ist es noch verlockender, schnell einen Prompt ohne Constraints einzutippen.
KI kann die Perspektiven betroffener Menschen nicht ersetzen. Die besten Korrektive kommen von:
- Betroffene Menschen: Personen aus der Zielgruppe, die beurteilen können, ob der Output angemessen, inklusiv und realistisch ist
- Kollegiale Beratung: Kolleg:innen mit anderen fachlichen Perspektiven und Lebenserfahrungen
- Intervision und Supervision: Strukturierte professionelle Reflexionsformate, die in der Sozialen Arbeit bereits existieren
Gaming Flyer: Das Event wurde komplett von Erwachsenen für Jugendliche geplant, ohne Beteiligung von Jugendlichen. Context Engineering kann KI-Output optimieren, aber partizipative Praxis nicht ersetzen.
Praxis: So holst du Community-Feedback ein
Wenn du wenig Zeit hast (5 Minuten): Zeig den KI-Output einer Person aus der Zielgruppe und frag: „Fühlt sich das für dich stimmig an? Was stört dich?" Keine Strukturierung nötig, die spontane Reaktion ist oft das wertvollste Feedback.
Wenn du mehr Zeit hast (in der Teamsitzung): Leg den KI-Output anonymisiert vor und lass das Team den Output-Check gemeinsam durchgehen. Verschiedene Fachkräfte finden verschiedene Probleme, genau darum geht es.
Wenn du es richtig machen willst (partizipativ): Binde die Zielgruppe nicht erst beim Feedback ein, sondern bereits bei der Aufgabenstellung. Statt „Ich habe einen Flyer mit KI erstellt, was sagt ihr dazu?" → „Wir wollen einen Flyer machen. Was soll drinstehen? Was nervt euch an solchen Flyern?" Dann den Input als Constraint in den Prompt einbauen.
Faustregel: Feedback einholen ist immer besser als kein Feedback, auch wenn es nur 5 Minuten sind, auch wenn es nur eine Person ist.
Dieser Leitfaden gibt dir keine abschließenden Antworten, dafür verändert sich die Technologie zu schnell. Was er dir gibt, ist eine Haltung: kritisch, reflektiert und handlungsfähig.
Du bist die Fachkraft. Die KI ist das Werkzeug. Behalt die Kontrolle.
Literaturverzeichnis
- Alon-Barkat, S. et al. (2024). Algorithmic discrimination in public service provision. Journal of Public Administration Research and Theory. DOI: 10.1093/jopart/muaf024
- Abend, S. (2025). Fördern ChatGPT und die DIN SPEC für Leichte Sprache die Teilhabe an Bildung? Zeitschrift für Heilpädagogik, 76(2), 67–70. DOI: 10.25656/01:32378
- Anh-Hoang et al. (2025). Survey and analysis of hallucinations in large language models. Frontiers in AI. DOI: 10.3389/frai.2025.1622292
- Barenkamp, M. (2025). Wertschöpfung durch KI: Chancen für Unternehmen und Gesellschaft. Springer Gabler. DOI: 10.1007/978-3-658-47482-9
- Bath, C. (2009). Searching for methodology: Feminist technology design in computer science.
- Bender, E. M. (2024). Resisting dehumanization in the age of "AI". Current Directions in Psychological Science, 33(2), 114–120. DOI: 10.1177/09637214231217286
- Bender, E. M. et al. (2021). On the dangers of stochastic parrots. FAccT '21, 610–623. DOI: 10.1145/3442188.3445922
- Bhadragiraiah, R. B., Kadirvel, S. & Rajashekar, C. K. (2024). Integrating artificial intelligence in social work: A meta-analysis. National Journal of Professional Social Work, 22(Special Issue), 19–32.
- Boetto, H. (2025). Artificial Intelligence in Social Work: An EPIC Model for Practice. Australian Social Work. DOI: 10.1080/0312407X.2025.2488345
- Carstensen, T. & Ganz, K. (2023). Vom Algorithmus diskriminiert? Zur Aushandlung von Gender in Diskursen über Künstliche Intelligenz und Arbeit. Working Paper Nr. 274, Hans-Böckler-Stiftung.
- Carstensen, T. & Ganz, K. (2024). Künstliche Intelligenz und Gender – eine Frage diskursiver (Gegen-)Macht? WSI-Mitteilungen. DOI: 10.5771/0342-300X-2024-1-26
- Chaiken, S. (1987). The heuristic model of persuasion. In: Zanna, M. P., Olson, J. M. & Herman, C. P. (Eds.), Social influence: The Ontario symposium (Vol. 5, S. 3–39). Lawrence Erlbaum Associates.
- Connell, R. (2014). Der gemachte Mann. Konstruktionen und Krise von Männlichkeiten. 4. Aufl., Springer VS.
- Criado-Perez, C. (2020). Unsichtbare Frauen. Wie eine von Daten beherrschte Welt die Hälfte der Bevölkerung ignoriert. Btb Verlag.
- de Beauvoir, S. (1949/2011). Das andere Geschlecht (Le Deuxième Sexe).
- Dellermann, D. et al. (2019). Hybrid intelligence. Business & Information Systems Engineering, 61(5), 637–643. DOI: 10.1007/s12599-019-00595-2
- Dominelli, L. (2002). Anti-oppressive social work theory and practice. Palgrave Macmillan.
- Dratsch, T. et al. (2023). Automation bias in mammography. Radiology. DOI: 10.1148/radiol.222176
- Duan, Y., Edwards, J. S. & Dwivedi, Y. K. (2019). Artificial intelligence for decision making in the era of Big Data. International Journal of Information Management. DOI: 10.1016/j.ijinfomgt.2019.01.021
- EASPD (2025). Unlocking the potential of artificial intelligence in social services.
- Enders, J. & Groschke, A. (2019). Geschlechterverhältnisse im Digitalen. In: Höfner, A. & Frick, V. (Hrsg.), Was Bits und Bäume verbindet (S. 94–97). Oekom.
- Eubanks, V. (2018). Automating Inequality. St. Martin's Press.
- Frey, C. B. & Osborne, M. A. (2017). The future of employment. Technological Forecasting and Social Change.
- Gausen, A., Mitra, B. & Lindley, S. (2024). A Framework for Exploring the Consequences of AI-Mediated Enterprise Knowledge Access. FAccT '24. DOI: 10.1145/3630106.3658900
- Greenwald, A. G. & Lai, C. K. (2020). Implicit Social Cognition. Annual Review of Psychology. DOI: 10.1146/annurev-psych-010419-050837
- Groen, M. & Tillmann, A. (2019). Let's play (gender)? In: Angenenet, H. et al. (Hrsg.), Digital Diversity (S. 143–159). Springer VS.
- Ho, Y. et al. (2025). Gender biases within AI and ChatGPT. Computers in Human Behavior: Artificial Humans. DOI: 10.1016/j.chbah.2025.100145
- Horwath, I. (2022). Algorithmen, KI und soziale Diskriminierung. In: Schnegg, K. et al. (Hrsg.), Inter- und multidisziplinäre Perspektiven der Geschlechterforschung. innsbruck university press.
- Kahn, L. et al. (2024). AI Safety and Automation Bias. CSET Georgetown.
- Kahneman, D., Slovic, P. & Tversky, A. (1982). Judgment under Uncertainty: Heuristics and Biases. Cambridge University Press.
- Karpathy, A. (2023). Intro to Large Language Models. YouTube
- Kasten, A., von Bose, K. & Kalender, U. (Hrsg.). (2022). Feminismen in der Sozialen Arbeit. Beltz Juventa.
- Kim, H.-Y. & McGill, A. L. (2024). AI-induced dehumanization. Journal of Consumer Psychology, 35(3), 363–381. DOI: 10.1002/jcpy.1441
- Kim, Y., Yang, Z. & Jung, Y. (2024). Persona prompting in large language models. arXiv:2408.08631
- Klinger, S., Sackl-Sharif, S., Mayr, A. & Brossmann-Handler, E. (2025). Digitale Soziale Arbeit. Universität Graz. digitalesozialearbeit.github.io
- Lazer, D. M. J. et al. (2020). Computational social science: Obstacles and opportunities. Science, 369(6507), 1060–1062. DOI: 10.1126/science.aaz8170
- Linnemann, G. A., Löhe, J. & Rottkemper, B. (2023). Bedeutung von KI in der Sozialen Arbeit. Soziale Passagen, 15, 197–211. DOI: 10.1007/s12592-023-00455-7
- Luccioni, A. S., Jernite, Y. & Strubell, E. (2024). Power Hungry Processing: Watts Driving the Cost of AI Deployment? ACM FAccT. DOI: 10.1145/3630106.3658542
- Lopez-Lopez, E. et al. (2025). Generative AI-mediated confirmation bias in health information seeking. Annals of the New York Academy of Sciences, 1550(1), 23–36. DOI: 10.1111/nyas.15413
- Mense, L. & Sera, S. (2019). Diversity in der Hochschullehre. In: Angenenet, H. et al. (Hrsg.), Digital Diversity (S. 197–214). Springer VS.
- Milestone, K. & Meyer, A. (2021). Gender and popular culture. 2. Aufl., Polity Press.
- Mohamed, A. et al. (2024). The Impact of Artificial Intelligence on Language Translation. IEEE Access. DOI: 10.1109/ACCESS.2024.3366802
- NASW (2025). The AI revolution in social work: NASW's call for action.
- NASW, ASWB, CSWE & CSWA (2017). Standards for technology in social work practice.
- Naveen, M. & Trojovský, P. (2024). Overview and challenges of machine translation. iScience. DOI: 10.1016/j.isci.2024.110878
- Noble, S. U. (2018). Algorithms of Oppression. NYU Press.
- Pavlidis, G. (2024). Unlocking the Black Box. Law, Innovation and Technology. DOI: 10.1080/17579961.2024.2313795
- Pelzl, J. (2025). IT-Sicherheit und Datenschutz im Kontext von KI-Sprachmodellen. In: Linnemann, G., Löhe, J. & Rottkemper, B. (Hrsg.), Künstliche Intelligenz in der Sozialen Arbeit: Grundlagen für Theorie und Praxis. Beltz Juventa.
- Petty, R. E. & Cacioppo, J. T. (1986). Communication and Persuasion. Springer. DOI: 10.1007/978-1-4612-4964-1
- Punz, J. (2015). Perspektiven intersektional orientierter Sozialer Arbeit. soziales_kapital, Nr. 13.
- Riegel, C. & Scharathow, W. (Hrsg.) (2012). Intersektionalität und Soziale Arbeit. VS Verlag.
- Rubin, M., Arnon, H., Huppert, J. & Perry, A. (2025). Comparing the value of perceived human versus AI-generated empathy. Nature Human Behaviour. DOI: 10.1038/s41562-025-02247-w
- Scambor, E. & Kurzmann, C. (2017). Intersektionale Gewaltprävention. In: Stuve, O. et al., Handbuch Intersektionale Gewaltprävention (IGIV). Dissens e.V., Berlin.
- Sanders, J. & Scanlon, E. (2021). The Digital Divide Is a Human Rights Issue. Journal of Human Rights and Social Work. DOI: 10.1007/s41134-020-00147-9
- Shrestha, A. & Das, K. (2022). Exploring gender biases in ML and AI academic research. Frontiers in AI. DOI: 10.3389/frai.2022.976838
- Shrestha, A., Ben-Menahem, S. M. & von Krogh, G. (2019). Organizational Decision-Making Structures in the Age of AI. California Management Review. DOI: 10.1177/0008125619862257
- Späte, J. et al. (Hrsg.) (2025). #GesellschaftBilden im Digitalzeitalter. Waxmann. DOI: 10.31244/9783830999973
- Steiner, R. & Tschopp, M. (2022). Künstliche Intelligenz in der Sozialen Arbeit. Sozial Extra. DOI: 10.1007/s12054-022-00546-4
- Strubell, E., Ganesh, A. & McCallum, A. (2019). Energy and Policy Considerations for Deep Learning in NLP. ACL. DOI: 10.18653/v1/P19-1355
- Stuve, O. et al. (2011). Handbuch Intersektionale Gewaltprävention (IGIV). Dissens e.V., Berlin.
- UNESCO (2023). Guidance on generative AI in education and research. DOI: 10.54675/EWZM9535
- Verordnung (EU) 2016/679. Datenschutz-Grundverordnung (DSGVO).
- Verordnung (EU) 2024/1689. EU AI Act.
- Walgenbach, K. (2017). Heterogenität – Intersektionalität – Diversity in der Erziehungswissenschaft. 2. Aufl., utb.
- Weber, J. (2026). Berichte schreiben in der sozialen Arbeit im Zeitalter künstlicher Intelligenz. Soziale Arbeit. DOI: 10.5771/0490-1606-2026-1-23
- Wilson, H. J. & Daugherty, P. R. (2018). Collaborative intelligence: Humans and AI are joining forces. Harvard Business Review, 96(4), 114–123.
- Wingerter, T. L., Straub, T. & Schweitzer, S. (2025). Mitigating automation bias in generative AI through nudges. Procedia Computer Science, 270, 2106–2114. DOI: 10.1016/j.procs.2025.09.331
- World Economic Forum (2025). The future of jobs report 2025.
- Xu, Z., Jain, S. & Kankanhalli, M. (2024). Hallucination is inevitable: An innate limitation of large language models. arXiv:2401.11817
Zitiervorschlag
Sabine Klinger, Josephine Jahn, Lisa Mittischek, Christopher Pollin, Susanne Sackl-Sharif, Christian Steiner, Susanne Richter & Arndt Schäfer (25.2.2026). Orientierungsleitfaden - Diversitätssensibler Umgang mit Künstlicher Intelligenz. Feministische AI Literacies und diversitätssensibles Prompting in der Sozialen Arbeit. https://digitalesozialearbeit.github.io/orientierungsleitfaden
Impressum
Herausgeber und Konzept
Forschungsprojekt: Diversitätssensibler Umgang mit Künstlicher Intelligenz. Digital/AI Literacies und feministisches Prompting in der Sozialen Arbeit.
Laufzeit: 01.07.2025 – 01.02.2026
Finanzierung: Elisabeth-List-Fellowship-Programm für Geschlechterforschung der Universität Graz
Homepage: Projektseite Universität Graz
Institut für Erziehungs- und Bildungswissenschaft, Universität Graz
Merangasse 70/II, 8010 Graz, Österreich
Projektleitung: Sabine Klinger
E-Mail: sabine.klinger@uni-graz.at